+
+

To integrate StatsD and Pingdom with your monitoring system, please reach out to MetricFire. Book a demo with the MetricFire team to discuss integrating StatsD and Pingdom and how that can support your monitoring system.
StatsD is an open-source network daemon that listens for statistics defined as counters, gauges, and timers sent via UDP, performs aggregation of this data, then sends it on to a configurable backend service - such as Hosted Graphite. You can use StatsD to perform such aggregation before sending your metrics to us by following this short guide:
{
port: 8125,
flushInterval: 10000,
graphitePort: 2003,
graphiteHost: "carbon.hostedgraphite.com",
graphite: {
legacyNamespace: false,
globalPrefix: "<your-api-key>"
}
}
The key benefit of using StatsD is the customizability. Unlike standard Agents, you can tailor StatsD to do exactly what you want. You can map out hundreds of metrics, give the metrics customized names, and have them sent into your monitoring backend. Once you collect and forward StatsD metrics to your Hosted Graphite account, you can use these metrics to build custom dashboards and alerts.
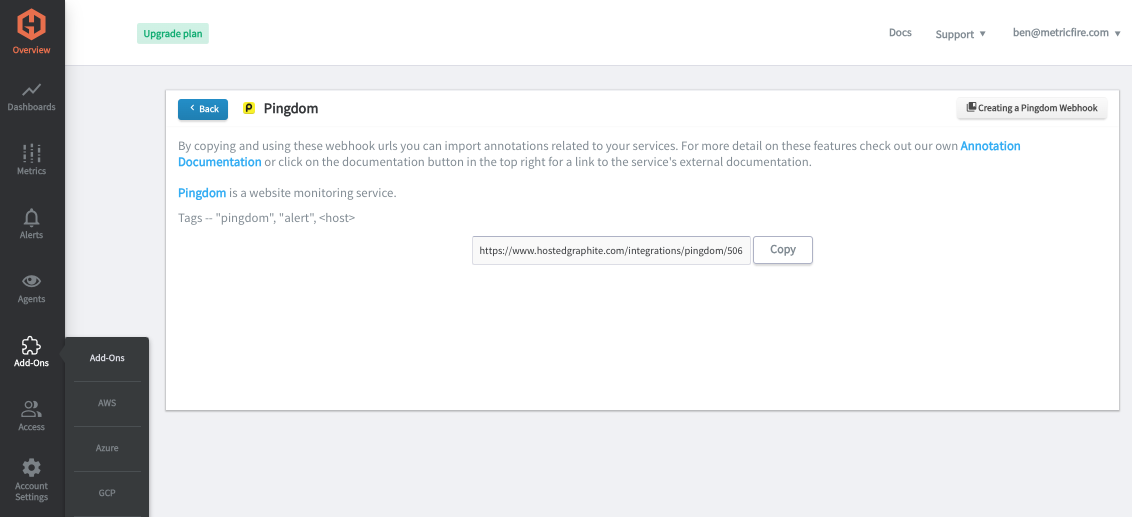
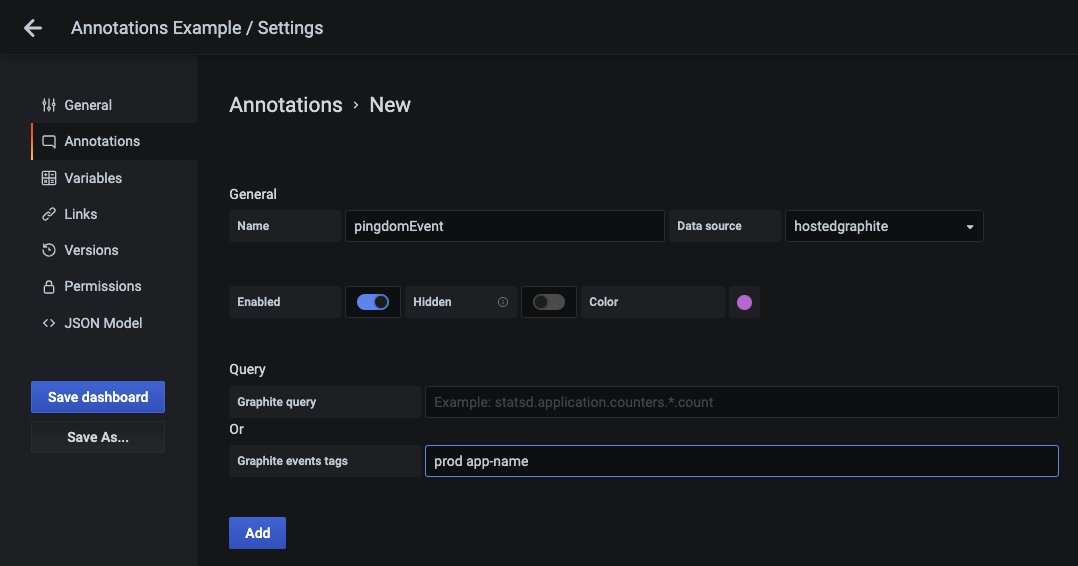
With a Pingdom webhook add-on, you can pinpoint your events in time to see if they coincide with changes in your metrics. Its easy to configure a Pingdom webhook in your Hosted Graphite account, configure it to Pingdom integrations, and visualize Pingdom events in the form of dashboard annotations. See the Hosted Graphite Pingdom docs for detailed configuration instructions.
You can visualize these events as annotations and query them by tags. More information on configuring annotations can be found in the Hosted Graphite annotations documentation:
MetricFire is a full-scale platform that provides infrastructure, system, and application monitoring using a suite of open-source tools. We will aggregate and store your data as time series metrics, which can be used to build custom dashboards and alerts. MetricFire takes away the burden of self-hosting your own monitoring solution, allowing you more time and freedom to work on your most important tasks.
MetricFire offers a complete ecosystem of end-to-end infrastructure monitoring, comprised of open-source Graphite and Grafana. MetricFire handles the aggregation, storage, and backups of your data, and offers alerting, team features, and API's for easy management of your monitoring environment. You can send server metrics using one of our agents, custom metrics from within your application code, and integration metrics from a variety of popular 3rd party services that we integrate with like Heroku, AWS, Azure, GCP, and many more!
Our Hosted Graphite product has improved upon standard Graphite to add data dimensionality, optimized storage, and offers additional tools and features that provide customers with a robust and well-rounded monitoring solution.
“We now have over ten times the amount of metrics we started with, and on different accounts. One of the great things about MetricFire is that scaling to support this increase has been hassle-free, requiring no additional work on our side.”
“Building and managing an on-premise installation at this scale would require a lot of engineer time, especially in the first year...we use this engineering time to work on initiatives closer to our core business”
“There’s complete transparency with everything MetricFire do which means we can accurately predict what we’ll be spending and comfortably keep within our budget.”
"Every time I have a question, I get an answer from support after just a couple of hours. Their technical knowledge is excellent.”
Monitoring SNMP devices is crucial for maintaining network health and security, enabling early detection... Continue Reading