
Table of Contents
Great systems are not just built. They are monitored.
MetricFire runs Graphite and Grafana as a fully managed service for growing engineering teams, taking care of storage, scaling, and version updates so your team doesn't have to. Plans start at $19/month, billed per metric namespace rather than per host, and include engineer-staffed support. Integrations work natively with Heroku, AWS, Azure, and GCP, and data is stored with 3× redundancy in SOC2- and ISO:27001-certified data centres.
Introduction
This article is part 2 of our 3-part Kubernetes CI/CD series. In the previous blog we discussed a general overview of various stages in a CI/CD workflow. Here we will dive deep into various continuous integration stages and discuss a production ready workflow for your Kubernetes applications.
An important aspect of CI/CD is proper visibility into the environment. Irrespective of what tool we use for our CI/CD pipelines we should make sure there is proper monitoring and notification in place to supplement it. Speak to us directly at MetricFire by booking a demo, and we'll help you plan how to best monitor your system as your code evolves. Check out our articles on Circle CI integrations and Github integrations for more info on how to use MetricFire with your CI pipeline, or sign up for our free trial and try it on your own.
Continuous Integration (CI) is the process of automating the building and testing of code every time a team member commits changes to version control. CI encourages developers to share their code and unit tests by merging their changes into a shared version control repository after every small task completion. Committing code triggers an automated build system to grab the latest code from the shared repository and to build, test, and validate the full master branch (also known as the trunk or main).
In the case of Kubernetes Applications we should understand that the deployable artifact is a Helm Chart/Kubernetes manifest. However, the helm chart is useless without the reference for the docker image. Therefore our CI system should not only Build and Test the docker image but also make sure that the helm chart to be deployed gets the same updates.
Some CI tools
Some widely used CI tools are:
- Jenkins
- Circle CI
- Travis CI
- Gitlab CI
- Semaphore CI
Each of these CI tools has its own advantages and disadvantages but the overall concept is the same. One challenge which teams face while working with a large number of tools is the portability. We should design the CI workflow in a manner which can be run both on the CI platform and locally on the dev machine. In order to solve this problem we use an extremely common yet very powerful tool called GNU Make.
Repo Structure
The source code repo should be organized as following:
$ tree -a myapp/
myapp/
├── charts
├── Dockerfile
├── Makefile
├── README.md
├── src
└── .travis.yml
src: This is the source code for the application.
README.md is the readme for this application which lists usage, instructions, and dependencies, etc.
Makefile: This is the master build file which will consume all other files/directories along with some environment variables to generate docker images and packaged helm charts.
Dockerfile: This is the dockerfile for the container running in the kubernetes pod.
Charts: This directory contains the helm chart which will be the deployable artifact for our Kubernetes cluster.
.travis.yml: This is the main CI configuration which will be consumed by travisCI to implement our workflow.
We will later go into details for different build targets which we will use in our Makefile.
Workflow
A sample CI pipeline looks something like the following:
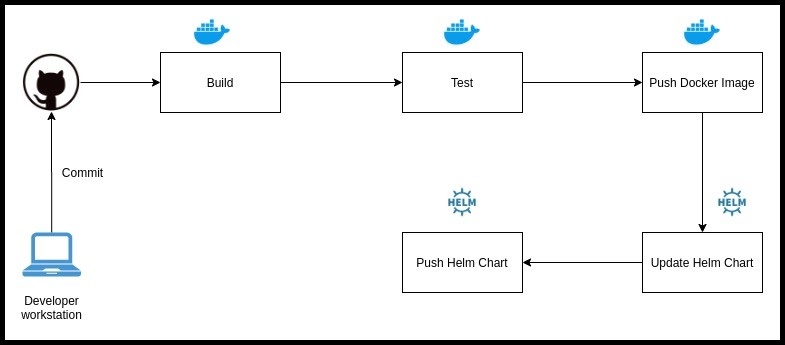
It can be explained in the following points:
- As soon as the Developer checks-in code to Git the CI pipeline gets triggered
1.1 This check-in could be to a Dev branch, Staging Branch or Master Branch
1.2 We recommend to run entire pipelines for a commit to a branch (or when a tag gets pushed)
1.3 In case of Pull Requests only the Build and Test stages should be run - Once the pipeline is kicked-off in the very first stage is to Build the docker image for the container to be run. This will primarily use the Dockerfile at the root of the repo, which in turn consumes application source code (src). The make target for the build process should look something like this:
export TAG := $(shell git rev-parse --short HEAD)
export APP := myapp
.PHONY: docker-build
docker-build:
$(info Make: Building docker images: TAG=${TAG})
docker build -t myrepo/myapp:${TAG} -f Dockerfile .
- After building the docker image, some Unit Tests are run on it. It is primarily the developer's responsibility to add enough Unit Tests in the application code. Already, In this stage we can scan our docker image for any kind of vulnerabilities. Trivy is a great tool which can be added to any CI pipeline. A simple vulnerability scan using Trivy can be run as following:
.PHONY: docker-scan
docker-scan:
$(info Make: Scanning docker images: TAG=${TAG})
make docker-build
docker run --rm -v $HOME:/root/.cache/ -v /var/run/docker.sock:/var/run/docker.sock aquasec/trivy --exit-code 0 --severity MEDIUM,HIGH --ignore-unfixed myrepo/myapp:${TAG}
You can choose to set the exit code in the scan command. This means that you can set Trivy to fail your build depending on the level of vulnerability you want to tolerate. For example:
$ docker run --rm -v $HOME:/root/.cache/ -v /var/run/docker.sock:/var/run/docker.sock aquasec/trivy --exit-code 1 --severity MEDIUM,HIGH,CRITICAL --ignore-unfixed nginx:1.13
2020-02-28T00:55:28.557Z INFO Detecting Debian vulnerabilities...
nginx:1.13 (debian 9.4)
=======================
Total: 84 (UNKNOWN: 0, LOW: 0, MEDIUM: 50, HIGH: 27, CRITICAL: 7)
+-------------------+------------------+----------+-------------------+-------------------+----------------------------------+
| LIBRARY | VULNERABILITY ID | SEVERITY | INSTALLED VERSION | FIXED VERSION | TITLE |
+-------------------+------------------+----------+-------------------+-------------------+----------------------------------+
| apt | CVE-2019-3462 | CRITICAL | 1.4.8 | 1.4.9 | Incorrect sanitation of the |
| | | | | | 302 redirect field in HTTP |
| | | | | | transport method of... |
+-------------------+------------------+----------+-------------------+-------------------+----------------------------------+
| e2fslibs | CVE-2019-5094 | MEDIUM | 1.43.4-2 | 1.43.4-2+deb9u1 | e2fsprogs: crafted |
| | | | | | ext4 partition leads to |
| | | | | | out-of-bounds write |
+-------------------+ + + + + +
| e2fsprogs | | | | | |
| | | | | | |
| | | | | | |
+-------------------+------------------+ +-------------------+-------------------+----------------------------------+
| gpgv | CVE-2018-12020 | | 2.1.18-8~deb9u1 | 2.1.18-8~deb9u2 | gnupg2: Improper sanitization |
| | | | | | of filenames allows for the |
| | | | | | display of fake status... |
+-------------------+------------------+----------+-------------------+-------------------+----------------------------------+
| libapt-pkg5.0 | CVE-2019-3462 | CRITICAL | 1.4.8 | 1.4.9 | Incorrect sanitation of the |
| | | | | | 302 redirect field in HTTP |
| | | | | | transport method of... |
+-------------------+------------------+ +-------------------+-------------------+----------------------------------+
| libc-bin | CVE-2017-16997 | | 2.24-11+deb9u3 | 2.24-11+deb9u4 | glibc: Incorrect handling of |
| | | | | | RPATH in elf/dl-load.c can be |
| | | | | | used to execute... |
+ +------------------+----------+ + +----------------------------------+
| | CVE-2017-1000408 | HIGH | | | glibc: Memory leak reachable |
| | | | | | via LD_HWCAP_MASK |
+ +------------------+ + + +----------------------------------+
| | CVE-2017-15670 | | | | glibc: Buffer overflow in glob |
| | | | | | with GLOB_TILDE |
+ +------------------+ + + +----------------------------------+
| | CVE-2017-15804 | | | | glibc: Buffer overflow during |
| | | | | | unescaping of user names with |
| | | | | | the ~ operator... |
+ +------------------+ + + +----------------------------------+
| | CVE-2017-18269 | | | | glibc: memory corruption in |
| | | | | | memcpy-sse2-unaligned.S |
+ +------------------+ + + +----------------------------------+
| | CVE-2018-11236 | | | | glibc: Integer overflow in |
| | | | | | stdlib/canonicalize.c on |
| | | | | | 32-bit architectures leading |
| | | | | | to stack-based buffer... |
+ +------------------+----------+ + +----------------------------------+
| | CVE-2017-1000409 | MEDIUM | | | glibc: Buffer overflow |
| | | | | | triggerable via |
| | | | | | LD_LIBRARY_PATH |
+ +------------------+ + + +----------------------------------+
| | CVE-2017-15671 | | | | glibc: Memory leak in glob |
| | | | | | with GLOB_TILDE |
+ +------------------+ + + +----------------------------------+
| | CVE-2018-11237 | | | | glibc: Buffer overflow in |
| | | | | | __mempcpy_avx512_no_vzeroupper |
+-------------------+------------------+----------+ + +----------------------------------+
$echo $?
1
The above command will fail the build because we have explicitly set the error code to 1 in case any vulnerability is detected.
- If the Test stage finishes successfully, we move on to Pushing the docker image to the image repository. This repository could be DockerHub, ECR, GCR, Quay or even a self hosted repo. The make target for the push process should look something like this:
.PHONY: docker-push
docker-push:
$(info Make: Building docker images: TAG=${TAG})
make docker-scan
docker push myrepo/myapp:${TAG}
- Now that we have pushed our image to the docker repo, it is time to Update the helm chart to reflect that change. We use a very handy shell utility called yq, in our makefile in order to achieve this. Also, feel free to use awk or sed magic if you find the result to be the same. The make target for helm chart build process should look something like this:
.PHONY: helm-test
test-helm:
$(info Make: Testing helm chart TAG=${TAG})
@sed -i -- "s/VERSION/${DATE}-${TAG}/g" chart/${CHART_NAME}/Chart.yaml
@sed -i -- "s/latest/${TAG}/g" charts/$(TAG)/Chart.yaml
@helm lint charts/${APP}
.PHONY: helm-build
push-helm:
$(info Make: Packaging helm chart TAG=${TAG})
make helm-test
@helm package --app-version=${TAG} --version=$(TAG) charts/${APP}
- After the docker image tag has been updated in the helm chart, we should package the helm chart and Store it in any kind of object store (AWS S3, GCP GCR, Jfrog Artifactory etc). Alternatively, you can also add the updated helm chart to a remote repo form which it can be fetched later on. The make target for helm chart push process should look something like this:
.PHONY: helm-push
push-helm:
$(info Make: Packaging helm chart TAG=${TAG})
make helm-buld
@curl -u ${ARTIFACTORY_USER}:${ARTIFACTORY_PASSWORD} -T ${APP}-${TAG}.tgz "${ARTIFACTORY_URL}/helm/${APP}/${TAG}.tgz"
It is important to understand that variables such as ${ARTIFACTORY_HOST} , ${ARTIFACTORY_USER} and ${ARTIFACTORY_PASSWORD} will be set as a part of the env depending upon the CI tool which we will be using (explained later). Similarly we should ensure that the credentials required to authenticate with the docker repository (in this example we will be using JFrog Artifactory for both docker and helm storage) are also present in the environment.
An important concept here is to understand that we are using git sha (short) to tag the images with the commit-id. The same convention is followed throughout the process and we subsequently generate helm charts with the same naming convention in order to maintain consistency.
Now all of these make targets will come together when you implement them in our CI configuration. Today we will take an example of TravisCI. The following .travis.yml consumes the makefile at the source of our repo and runs our entire pipeline.
sudo: required
dist: xenial
services:
- docker
addons:
snaps:
- name: yq
classic: true
- name: helm
classic: true
env:
global:
- ARTIFACTORY_URL="https://myorg.jfrog.io/"
# travis encrypt ARTIFACTORY_PASSWORD=$(ARTIFACTORY_PASS)
- secure: "BdfrOIoKvHUAYGORKuvlrRfEl4OmNF9ypO+I+F6RmSvNUAqYi7/7ZE="
# travis encrypt ARTIFACTORY_USERNAME=$(ARTIFACTORY_USER)
- secure: "QSm6e3HC0SEyCl+lqil/8ZDgxm5E/xTx0hvf0mS/i+Bug8qv7vpo0BI="
before_install:
- echo $ARTIFACTORY_PASS | docker login -u $ARTIFACTORY_USER --password-stdin $ARTIFACTORY_URL
- helm init --client-only
jobs:
include:
- stage: Build Docker Images
name: "Build Docker images and run tests"
script:
# Building images
- make docker-build
- stage: Scan Docker Images
name: "Scan Docker images"
script:
# Building images
- make docker-scan
- stage: Publish Docker Images
name: "Push Docker images”
if: branch = master
script:
# Pushing tagged images
- make docker-push
- stage: Build Helm Chart
name: "Build Helm Chart”
script:
# Build Helm Chart
- make helm-build
- stage: Test Helm Chart
name: "Test Helm Chart”
script:
# Test Helm Chart
- make helm-build
- stage: Push Helm Chart
name: "Push Helm Chart”
if: branch = master
Script:
# Push Helm Chart to repo
- make helm-push
#travis encrypt "<account>:<token>#channel" --add notifications.slack.rooms
notifications:
slack:
rooms:
- secure: "sdfusdhfsdofguhdfgbdsifgudwbiervkjngidsuag34522irueg="
on_success: always
on_failure: always
Important things to note:
- We are pushing docker images and helm charts for the master branch only.
- In every other case, we build, test and scan the docker images and the helm chart. This ensures that when code gets merged to the master branch, at least all Unit tests are passing, it is free from vulnerabilities, and it compiles properly.
- We can always have more complex scenarios where a build can be triggered when:
3.1 A tag which follows a certain naming convention gets pushed
3.2 A scheduled run of the pipeline takes place
3.3 A particular branch is pushed to. - We have also added a notification section where the slack account, token and the channel name have been encrypted. Notifications form a very crucial aspect of any CI pipeline and it is always nice to have them delivered to slack. You can create complex notification scenarios for various branch or tagged builds as well. Additionally, other delivery mechanisms such as email, hipchat, or even webhooks can be configured. Details of the configuration can be found here.
We will cover the detailed deployment aspect for these builds in the next blog, but it is important to understand that docker images and helm charts can be built and published in a number of scenarios such as a commit to master, commit to staging branch or pushing a tag etc. However, during the handoff from Continuous Integration to Continuous Delivery we should relay the build scenario information to the Continuous Delivery system. It is important because using that information the CD system will decide whether the application should be deployed to the development environment, staging or production.
Conclusion
The configuration and strategy discussed in this blog post has been tested in production use cases. However, understand that every application is different and so is its environment. We hope this blog has provided you with enough insight to develop a strategy befitting your application's environment and business needs.
You are more than welcome to reach out with questions related to this blog or if you would like to brainstorm scenarios specific to your use case. Make sure you sign up for our trial to learn more about how you can monitor your workloads while your CI/CD pipelines roll out new versions.
Also, reach out to us by booking a demo. We can help you design good monitoring strategies for Kubernetes CI/CD, and get you set up with the monitoring that your company needs.

