Table of Contents
Great systems are not just built. They are monitored.
MetricFire runs Graphite and Grafana as a fully managed service for growing engineering teams, taking care of storage, scaling, and version updates so your team doesn't have to. Plans start at $19/month, billed per metric namespace rather than per host, and include engineer-staffed support. Integrations work natively with Heroku, AWS, Azure, and GCP, and data is stored with 3× redundancy in SOC2- and ISO:27001-certified data centres.
Introduction
I used to think my job as a developer was done once I trained and deployed the machine learning model. Little did I know that deployment is only the first step! Making sure my tech baby is doing fine in the real world is equally important. Fortunately, this can be done with machine learning monitoring.
In this article, we’ll discuss what can go wrong with our machine-learning model after deployment and how to keep it in check. Later on, we will also cover machine learning monitoring using MetricFire’s Hosted Graphite platform.
What is MetricFire, you may ask? Good question.
MetricFire specializes in monitoring systems with minimal configuration to save you the cost of DIY monitoring. Know more about the platform by signing up for a free trial or booking a demo.
But first, why should I care about monitoring machine learning models?
Why should I monitor Machine Learning Models?
The software development life cycle tells us our model should work as expected. After all, we have spent hours testing and perfecting it on our data. But that’s the point - it’s a software development life cycle. Machine learning models behave differently than conventional software models. They are dynamic which makes them pretty useful and versatile but it also makes them sensitive to changes in the real world.
Besides the fact that machine learning models are vulnerable to data issues and hence should be validated, we also need to know if our model is actually doing any good. Is it making our services better by solving the problems it was intended to solve? How and how well is it solving those problems?
Indeed, the validation results during the development phase justify the production of the model but it shouldn’t just stop there. Monitoring it after deployment makes sure the performance stays that way.
The moral of the story is:
-
Machine Learning models are different from software models.
-
Monitoring them is crucial.
The next question is - what to expect?
What can go wrong with your machine-learning model?
There are 2 common data issues you may encounter:
-
Problems with the data itself
-
Problems with the environment
There could be plenty of reasons why this happens. As trivial as it sounds, you might just be receiving corrupted data to begin with.
Issues with the Data
Consider a scenario where you work for a finance company. The company has decided to roll out a newsletter with personalized offers for its valuable customers. The offers are based on the internal user database, recent transactions or purchases, app usage, etc. These data sources may be managed by different teams within the company. During the development process, you have access to all the data and can work out the algorithm accordingly.
However, since our input data depends on the combination of all these data sources, there is plenty of room for things to go wrong after deployment. To ensure reliable data access across your organization, you might consider using a DreamFactory, a self-hosted platform that provides governed API access to any data source, ensuring that your ML models can reliably access the data they need from multiple sources with proper role-based access controls and security.
-
If one of these services is managed manually, a trivial data entry error can mess up the input data.
-
You forgot to account for corner cases so your query may not be valid for all cases.
-
Input data might be using an older version of the repository.
-
Permission Error because your data storage location has changed.
These are some of the examples where the input data faces preprocessing issues.
Let’s see what happens when the environment changes.
Issues with the Environment
Another case when your model might behave differently even though it is receiving the correct data is because the environment has changed. This is often referred to as “model staleness” where the predictive power of your model decreases over time. This is because trends change and while your machine learning model is dynamic, it’s not prepared for encountering a different pattern of data altogether.
Let’s take a look at perhaps the most recent and relatable example - the pandemic!
Covid-19 affected the market in an unprecedented way. Since a lot of people lost their jobs at around the same time, the financial condition of the families also changed. This meant different shopping patterns which previously developed predictive models weren’t prepared for.
For example, lipstick sales decreased significantly because people went behind masks. On the other hand, skin care and eye makeup products saw an increase. In hindsight, it sure seems intuitive however the changes in the environment may have resulted in the model faltering.
Now that we know that things can go wrong with our machine learning model, the next question is how to prevent it.
Well, ideally, we never want to let these problems occur in the first place but it can be complicated. A more realistic approach would be to catch it before it’s too late!
What metrics to monitor?
What metrics to monitor depends on the kind of monitoring approach we plan to take. There are mainly 2 kinds of machine learning monitoring:
-
Functional Monitoring: Monitoring the data, model, and output (everything to do with the model)
-
Operational Monitoring: Monitoring the system usage and cost (everything to do with the resources)
The issues we mentioned before - something going wrong either with the data or with the environment come under the category of Functional Monitoring.
The first problem that we discussed dealt with the input data being different or corrupted.
Dealing with Data Integrity
Making sure that the data schema for deployment and development is identical can be one of the simple steps to take. This will save us money, time, and headaches. It can be done via:
-
Checking the feature set: Have we changed any feature names recently? Are we missing anything?
-
Checking the data type: This goes without saying but are we receiving the output in a different data type than we expected such as - categorical vs. numerical?
Okay, now we have made sure that our input data is in the proper format. Next, we also want to validate that the schema in deployment does not change over time. The concept is often referred to as data or concept drift.
If the probability of input data changes either because of a change in the feature set (e.g. adding a new feature) or changes in the real world (e.g. pandemic), then it’s called data drift.
On the other hand, concept drift occurs if the relationship between the input variables and the target variable alters over time.
Dealing with Data Drift
Data drift essentially occurs because the distribution of the features has changed. The following statistical tests can help with that:
-
Z-score test: The differences between the distribution of training and production data can be measured by the z-score test. If the z-score is significant enough, there is a chance that data drift has occurred.
-
Kolmogorov–Smirnov (KS) Test: This test can help detect whether the distribution in the training phase is identical to that of the input data in production. If the result is statistically significant indicating that the distribution is not the same, then the null hypothesis is rejected.
Dealing with Concept Drift
We can detect concept drift if the prediction probability of the output changes over time given the same input. For example, Covid-19 changed shopping patterns all over the world. The sales of skincare products saw a sudden increase. Our old models did not account for this.
Here’s how we can improve:
-
Performance Monitoring: Monitoring the performance metrics such as Mean Squared Error (MSE) for regression models or accuracy for classification models, is crucial. Consistent monitoring ensures that the model is performing as expected.
-
Model Retraining: The performance of machine learning models tends to degrade over time. The key is to retrain our model before it becomes unacceptable. For instance, if our model gets stale every 4 months, retrain it every 3 months.
There are tons of machine learning monitoring tools available online to help us with such monitoring. Graphite is one such platform.
Machine Learning Monitoring with Graphite
Graphite lets you query your data in real-time and also allows you to use it for visualization. But why is this important? Real-time monitoring helps us detect any anomalies or alterations in patterns quickly. So, we can make changes to our model without losing our business.
Monitoring with Graphite has been made easy with MetricFire’s Hosted Graphite service. Book a free demo to get started. I also liked this blog on installation and setup which covers everything step-by-step.
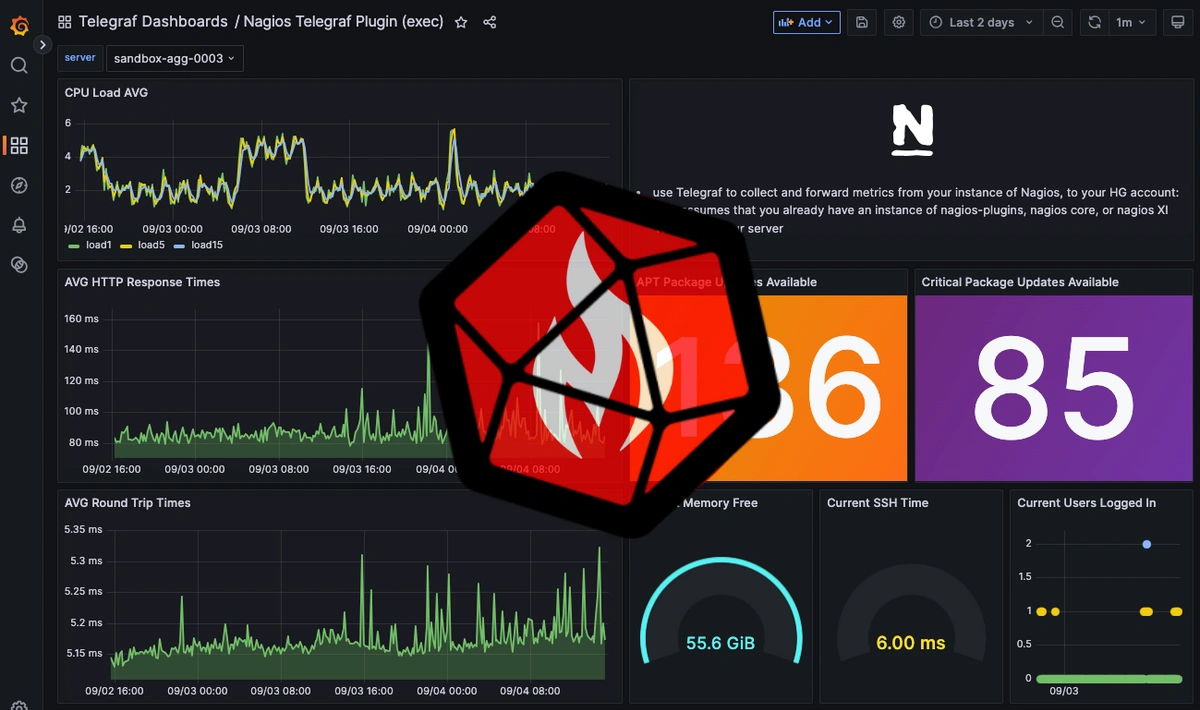
After the installation, you can also create a dashboard with a customizable layout. This makes it much easier to monitor different metrics in just one place.
Conclusion
In this blog, we discussed why it is crucial to monitor machine learning models and how it is different from software models. We also saw different kinds of data issues and how to take care of them. Furthermore, we discussed several metrics and statistical tests to monitor machine learning models based on the data issue.
Lastly, we covered how MetricFire can help you with monitoring machine learning models and also save you the cost of DIY Monitoring.
MetricFire provides a Hosted version of Graphite to store your data for two years, a complete tool Grafana for data visualization, and much more. If you would like to learn more about it, please book a demo with us, or sign on to the free trial today.