
Table of Contents
Great systems are not just built. They are monitored.
MetricFire runs Graphite and Grafana as a fully managed service for growing engineering teams, taking care of storage, scaling, and version updates so your team doesn't have to. Plans start at $19/month, billed per metric namespace rather than per host, and include engineer-staffed support. Integrations work natively with Heroku, AWS, Azure, and GCP, and data is stored with 3× redundancy in SOC2- and ISO:27001-certified data centres.
はじめに
このチュートリアルを通じて、TelegrafエージェントをDaemonSetとして導入し、ノードやPodのメトリクスをデータソースへ送信することで、Kubernetesクラスターを手軽に監視できるようになります。収集したデータをもとに、カスタムダッシュボードやアラートも簡単に構築可能です。わずか数分で実現できる内容となっておりますので、ぜひご参照ください。
Kubernetesは、コンテナ化されたアプリケーションのデプロイ、スケーリング、管理を自動化するために、本番環境レベルのアプリケーションやソフトウェアサービスで広く利用されています。ロードバランシング、自己修復、ローリングアップデートなどの機能により、分散システム全体で高い可用性と安定したパフォーマンスを実現します。また、クラウドネイティブおよびハイブリッド環境において効率的なリソース活用とオーケストレーションを可能にし、近年その人気は急速に高まっています。現在では、世界中でソフトウェアインフラを管理するための重要なプラットフォームとなっています。
Kubernetesクラスターの監視は、リソース使用の最適化やアプリケーションのパフォーマンス維持において非常に重要です。問題を早期に検知し迅速に対応できるだけでなく、異常な挙動の可視化によってセキュリティの強化にもつながります。また、規制要件への準拠を支援し、コスト管理やキャパシティプランニングにも役立ちます。これにより、動的な環境におけるサービスの信頼性と可用性を確保できます。
前提条件
本記事では、稼働中のKubernetesクラスターにアクセスできることを前提としています。まだお持ちでない場合は、Docker Desktop上のminikubeなどのツールや、AWS EKSやLinodeのようなマネージドサービスを利用してテスト用クラスターを立ち上げることができます。本例では、Linode上でホストされているクラスターからメトリクスを収集しています。
次に、メトリクスを転送するためのデータソースも必要です。無料かつ簡単に設定できるデータソースとして、Hosted GraphiteおよびGrafanaを提供するMetricFireのトライアルに登録することができます。トライアルアカウントに登録すると、後続の手順で使用するAPIキーが発行されます。
最後に、TelegrafをDaemonSetとしてクラスターにデプロイします。そのためには、コマンドライン上でkubectlツールがインストールされていること、そして~/.kube/configファイルにクラスターのコンテキストと認証情報(certificate-authority-data、token)が正しく設定されている必要があります。
Kubernetesクラスターが起動しており、~/.kube/configファイルがCLIからのアクセスを許可するように設定されている場合、以下のコマンドでコンテキストを設定できます:
- kubectl config get-contexts
- kubectl config use-context <context-name>
Telegraf DaemonSetのファイル構成を作成
DaemonSetのデプロイは、一般的にYAMLファイルの構成によって管理されます。Helmチャートは、これらのファイルを自動的に作成するためのフレームワーク(ボイラープレート)のような役割を果たすため、よく利用されています。しかし、Helmチャートほどの複雑さが不要な場合、Kustomizeツールは優れた選択肢となります。Kustomizeはkubectlに標準で組み込まれているため、デプロイ管理を簡単に行うことができます。以下では、Kustomizeコマンドラインツールを使用してTelegrafエージェントをDaemonSetとしてデプロイするための基本的なファイル構成について説明します。各ディレクトリやファイルはローカル環境で手動作成することもできますし、MetricFireのGitHub公開リポジトリをクローンすることも可能です。
プロジェクトディレクトリ構成:
telegraf-daemonset/
├── kustomization.yaml
└── resources/
├── config.yaml
├── daemonset.yaml
├── namespace.yaml
├── role.yaml
├── role-binding.yaml
└── service_account.yaml
kustomization.yaml:このファイルはオーケストレーターとして機能し、他のすべてのYAMLファイルをまとめ、追加の設定やパッチを適用します。これにより、環境間で一貫性のある再現可能なデプロイが保証されます。
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: monitoring
resources:
- resources/config.yaml
- resources/daemonset.yaml
- resources/namespace.yaml
- resources/role-binding.yaml
- resources/role.yaml
- resources/service_account.yaml
resources/config.yaml:このファイルには、DaemonSetや他のKubernetesリソースで必要となる設定データが含まれます。Telegrafの場合、通常はinput/outputプラグインとその設定が含まれます。このファイルはKubernetesのConfigMapとして使用され、DaemonSetに設定データを提供します。デフォルトのパフォーマンス収集プラグインに加えて、ここでは inputs.kubernetes プラグインと outputs.graphite プラグインを設定します。これにより、データはHosted Graphiteのトライアルアカウントへ転送されます(このファイルには必ずHGのAPIキーを追加してください)。
apiVersion: v1
kind: ConfigMap
metadata:
name: telegraf-config
data:
telegraf.conf: |
[agent]
hostname = "$HOSTNAME"
interval = "10s"
round_interval = true
[[inputs.cpu]]
percpu = false ## setting to 'false' limits the number of cpu metrics returned
[[inputs.disk]]
ignore_fs = ["tmpfs", "devtmpfs", "devfs", "iso9660", "overlay", "aufs", "squashfs"]
# [[inputs.diskio]] ## commented out to limit the number of metrics returned
[[inputs.mem]]
[[inputs.system]]
[[outputs.graphite]]
servers = ["carbon.hostedgraphite.com:2003"]
prefix = "<YOUR-HG-API-KEY>.telegraf-k8"
[[inputs.kubernetes]]
url = "https://$HOSTIP:10250"
bearer_token = "/var/run/secrets/kubernetes.io/serviceaccount/token"
insecure_skip_verify = true
resources/daemonset.yaml:このファイルはKubernetesのDaemonSetリソースを定義します。DaemonSetは、クラスター内のすべて(または一部)のノード上でPodのコピーが実行されることを保証します。コンテナイメージ、リソース制限、ボリュームなど、Podテンプレートの仕様が含まれます。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: telegraf
spec:
selector:
matchLabels:
name: telegraf
template:
metadata:
labels:
name: telegraf
spec:
serviceAccountName: telegraf-sa
containers:
- name: telegraf
image: telegraf:latest
resources:
limits:
memory: 200Mi
cpu: 200m
requests:
memory: 100Mi
cpu: 100m
volumeMounts:
- name: config
mountPath: /etc/telegraf/telegraf.conf
subPath: telegraf.conf
- name: docker-socket
mountPath: /var/run/docker.sock
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: hostfsro
mountPath: /hostfs
readOnly: true
env:
# This pulls HOSTNAME from the node, not the pod.
- name: HOSTNAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
# In test clusters where hostnames are resolved in /etc/hosts on each node,
# the HOSTNAME is not resolvable from inside containers
# So inject the host IP as well
- name: HOSTIP
valueFrom:
fieldRef:
fieldPath: status.hostIP
# Mount the host filesystem and set the appropriate env variables.
# ref: https://github.com/influxdata/telegraf/blob/master/docs/FAQ.md
# HOST_PROC is required by the cpu, disk, mem, input plugins
- name: "HOST_PROC"
value: "/hostfs/proc"
# HOST_SYS is required by the diskio plugin
- name: "HOST_SYS"
value: "/hostfs/sys"
- name: "HOST_MOUNT_PREFIX"
value: "/hostfs"
volumes:
- name: hostfsro
hostPath:
path: /
- name: config
configMap:
name: telegraf-config
- name: docker-socket
hostPath:
path: /var/run/docker.sock
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
resources/namespace.yaml:Namespaceは、クラスター内のリソースを論理的に分離するために使用されます。このファイルは、DaemonSetに関連するすべてのリソースが指定されたNamespaceにデプロイされることを保証します。
apiVersion: v1
kind: Namespace
metadata:
name: monitoring
resources/role.yaml:Roleは、Namespace内のリソースへのアクセス権を付与するために使用されます。このファイルでは、DaemonSetで使用されるサービスアカウントが、どのリソースに対してどの操作を実行できるかを定義します。
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: telegraf-cluster-role
rules:
- apiGroups: ["metrics.k8s.io"]
resources: ["pods"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["nodes", "nodes/proxy", "nodes/stats", "persistentvolumes"]
verbs: ["get", "list", "watch"]
resources/role-binding.yaml:このファイルは、Roleをユーザー、グループ、またはサービスアカウントにバインドします。指定されたNamespace内で、誰がRoleで定義された操作を実行できるかを指定します。
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: telegraf-sa-binding
subjects:
- kind: ServiceAccount
name: telegraf-sa
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: telegraf-cluster-role
resources/service_account.yaml:サービスアカウントは、Pod内で実行されるプロセスに対して識別情報を提供します。Kubernetes APIサーバーとの認証に使用され、クラスターリソースとやり取りするPodに関連付けられます。
apiVersion: v1
kind: ServiceAccount
metadata:
name: telegraf-sa
Telegraf DaemonSetのデプロイ
この時点で、プロジェクトディレクトリには kustomization.yaml ファイルと、他の6つのYAMLファイルを含む resources ディレクトリが存在しているはずです。
すでに正しいクラスターコンテキストを使用している前提で、まずテスト(ドライラン)を実行し、その後 kustomization.yaml をプロジェクトのルートディレクトリからデプロイできます:
- kubectl apply -k . --dry-run=client
- kubectl apply -k .
期待される出力:
namespace/monitoring created
serviceaccount/telegraf-sa created
clusterrole.rbac.authorization.k8s.io/telegraf-cluster-role created
clusterrolebinding.rbac.authorization.k8s.io/telegraf-sa-binding created
configmap/telegraf-config created
daemonset.apps/telegraf created
これで、クラスター内で実行中のDaemonSetの一覧を取得でき、「Name」が telegraf、「Namespace」が monitoring のものが表示されるはずです:
- kubectl get daemonsets --all-namespaces
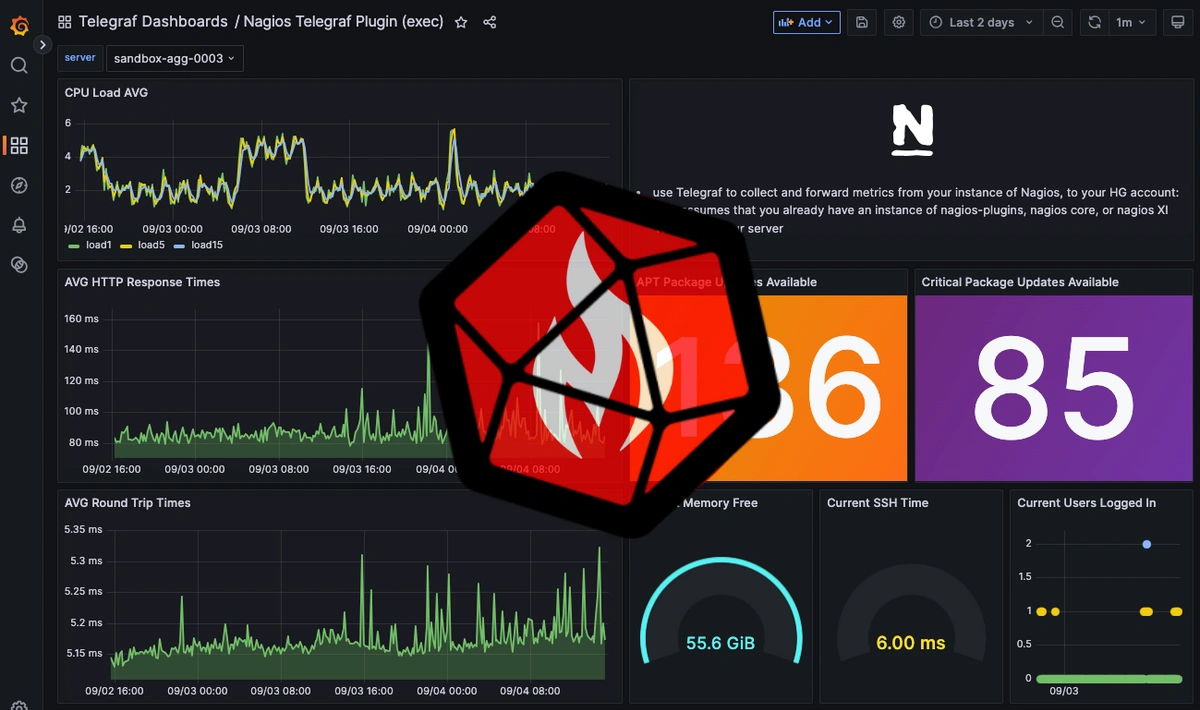
Telegrafは、ノードおよびPodのコンテナ/ボリューム/ネットワークのメトリクスを収集し、Hosted Graphiteのトライアルアカウントへ転送します。これらのメトリクスはGraphite形式で送信され、HG上でカスタムダッシュボードやアラートの作成に利用できます。詳細や追加の設定オプションについては、inputs.kubernetes プラグインの公式GitHubリポジトリをご参照ください。
メトリクスの確認と可視化
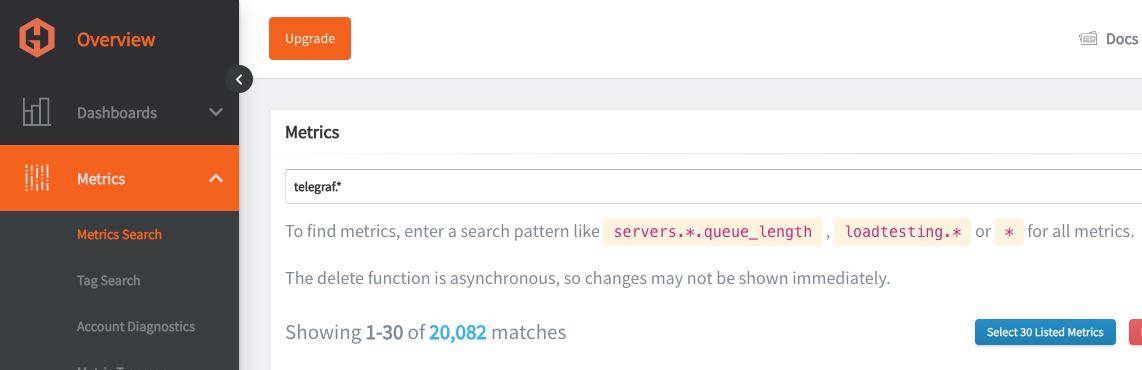
Hosted Graphiteのトライアルアカウントにログインし、Metrics Search に移動します。メトリクスには「Telegraf」というプレフィックスが付いているため、それを検索条件として使用することで、Graphiteメトリクスの一覧を表示できます。
 \
\
次に、Dashboards → Primary Dashboards に移動し、「+」ボタンをクリックして新しいパネルを作成します。EditモードのクエリUIを使用して、Graphiteのメトリクスパスを選択します(HGでは、デフォルトのデータソースはHosted Graphiteのバックエンドになります)。ダッシュボードの作成方法や、変数・アノテーション・Graphite関数などの高度な機能の利用方法については、HGのダッシュボードドキュメントをご参照ください。
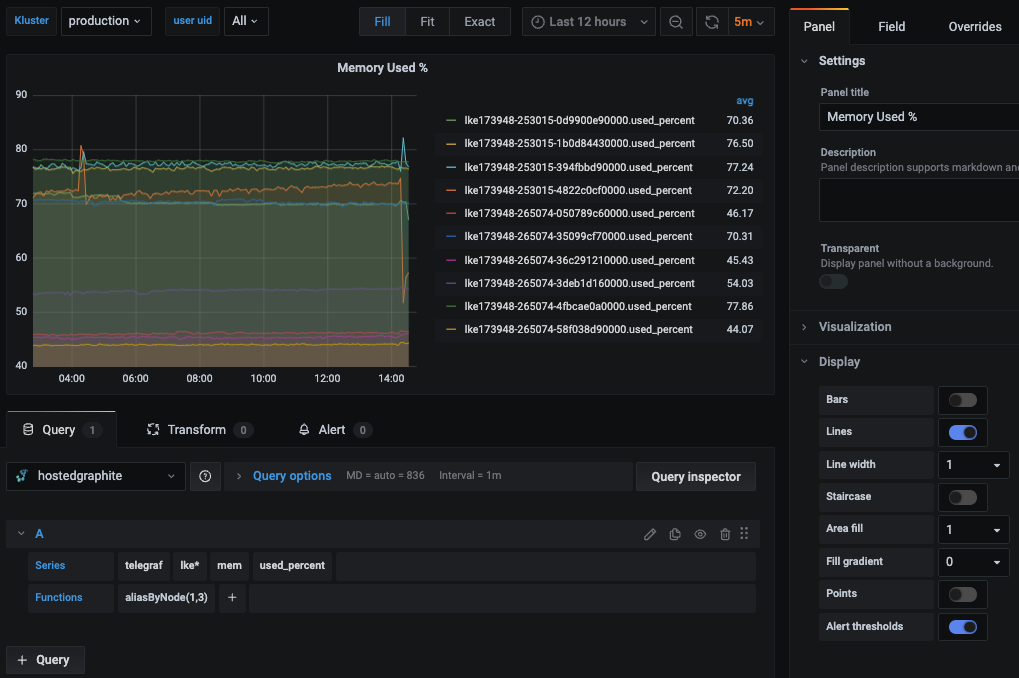
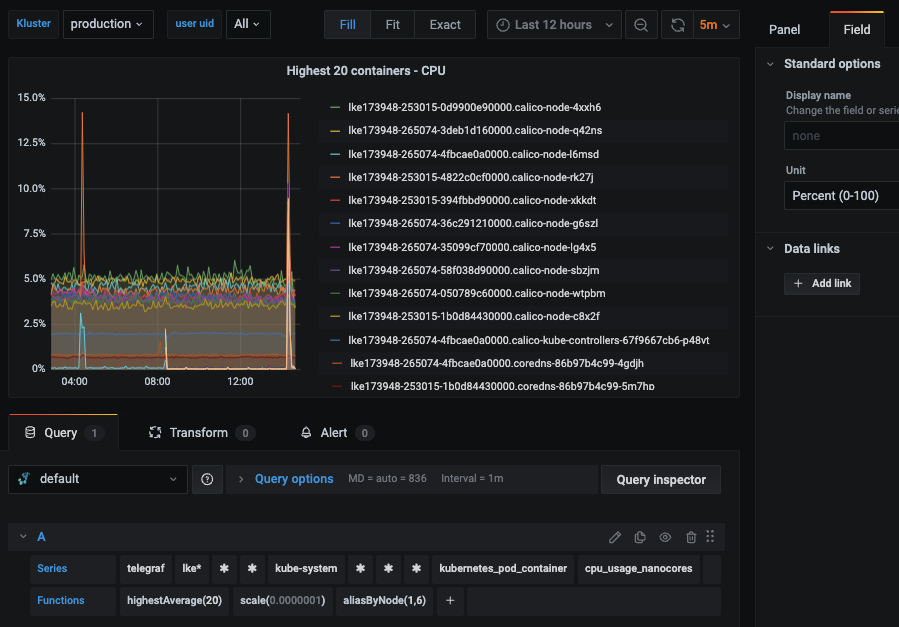
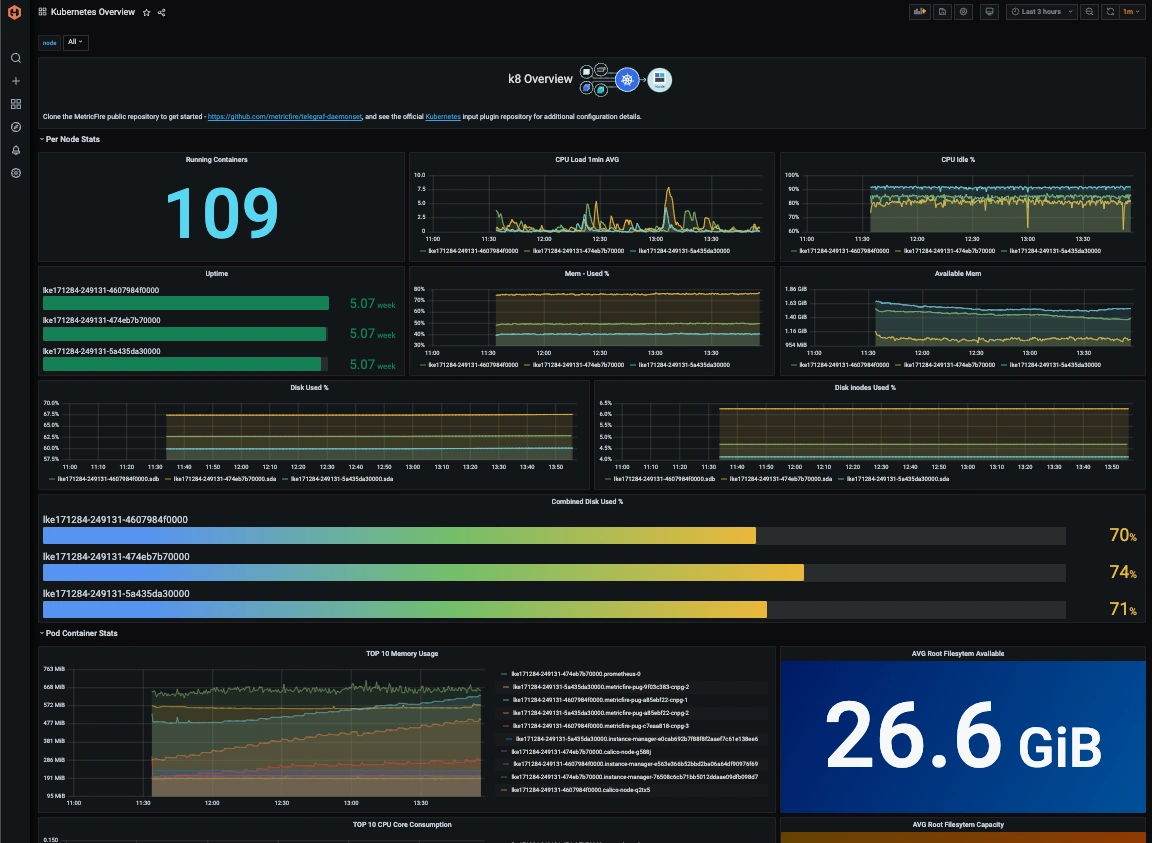
また、Hosted Graphiteのダッシュボードライブラリに移動し、あらかじめ用意されたKubernetes Overviewダッシュボードを生成することもできます。これは、telegraf-k8メトリクスと互換性があります。
Graphiteアラートの設定
Hosted GraphiteのUIで、Alerts → Graphite Alerts に移動し、新しいアラートを作成します。アラートに名前を付け、アラート対象となるメトリクスのクエリを入力し、このアラートの内容を説明として追加します。
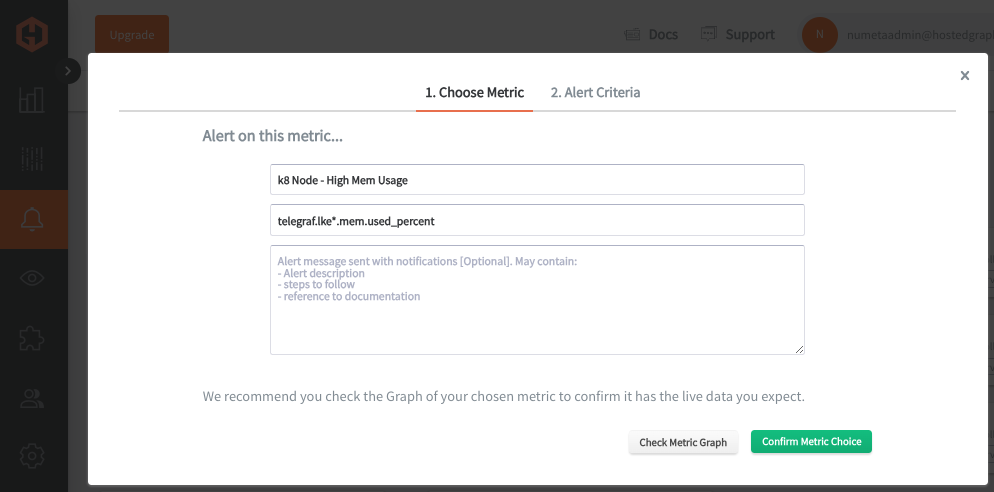
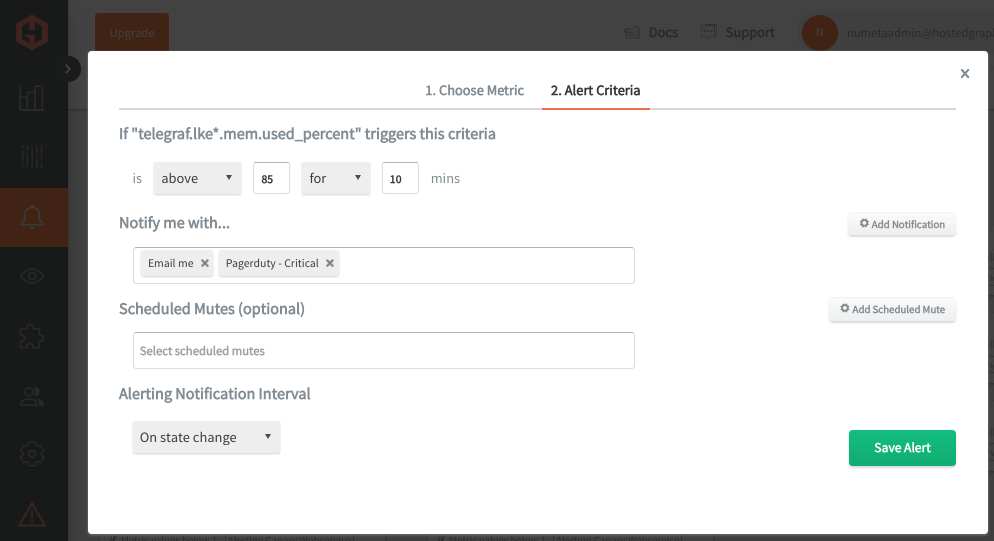
次に、Alert Criteria タブを選択して、しきい値や通知チャネルを定義します。デフォルトの通知チャネルは、Hosted Graphiteアカウント登録時に使用したメールアドレスになります。Slack、PagerDuty、Microsoft Teams、OpsGenie、カスタムWebhookなど、追加の通知チャネルも簡単に設定できます。通知チャネルの詳細については、Hosted Graphiteのドキュメントをご参照ください。
まとめ
Kubernetesインフラの可視性を確保することは、最適なパフォーマンス、セキュリティ、効率的なリソース管理を実現するうえで非常に重要です。これにより、異常の検知、問題の診断、そしてスケーリングやリソース配分に関する適切な意思決定が可能になります。TelegrafをDaemonSetとして使用してGraphiteデータを収集する方法は、各ノードに自動的にTelegrafをデプロイできるため、手動対応なしで包括的なデータ収集を実現できる点で便利です。このアプローチは、Telegrafの豊富な入力プラグインを活用し、多様なメトリクスを収集することで、クラスター全体にわたる一元的で一貫性のある監視環境を提供します。
ダッシュボードやアラートなどのツールは、リアルタイムの可視化、問題の早期検知、過去データのトレンド分析、そして意思決定の支援を通じて、収集したデータの価値をさらに高めます。これらは、堅牢で効率的なインフラを維持するために不可欠な要素です。
Hosted GraphiteおよびGrafanaサービスの無料トライアルにぜひご登録ください。製品に関するご質問や、MetricFireがどのように貴社の課題解決を支援できるかについては、デモをご予約いただき、直接ご相談ください。