
Table of Contents
Great systems are not just built. They are monitored.
MetricFire runs Graphite and Grafana as a fully managed service for growing engineering teams, taking care of storage, scaling, and version updates so your team doesn't have to. Plans start at $19/month, billed per metric namespace rather than per host, and include engineer-staffed support. Integrations work natively with Heroku, AWS, Azure, and GCP, and data is stored with 3× redundancy in SOC2- and ISO:27001-certified data centres.
はじめに
Lokiは、Grafanaによって開発された強力かつスケーラブルなログ集約システムであり、ログを効率的に収集、保存、検索するために設計されています。現代的なオブザーバビリティスタックの一部として、Prometheusと組み合わせて導入されることが多くあります。Lokiはメタデータのみをインデックス化する設計を採用しており、コスト効率の高いストレージを実現しているため、大規模なログ環境に適した選択肢です。
しかし、Lokiはログ取り込みやインデックス作成に優れている一方で、多くのチームはLoki自体を監視するという重要な作業を見落としています。Loki自身のパフォーマンス、例えば取り込みレート、クエリ遅延、キャッシュ効率、リソース使用率などを可視化できなければ、ボトルネックの検知や、ユーザーへ影響が出る前の障害予防が難しくなります。
本記事では、Telegrafエージェントを使用してLokiのパフォーマンスメトリクスを収集・変換し、無料のデータソースへ転送する方法を詳しく解説します。
Telegrafエージェントの始め方
Telegrafは、InfluxDB上に構築されたプラグインベースのサーバーエージェントであり、データベース、システム、プロセス、デバイス、アプリケーションからメトリクスやイベントを収集・送信します。Go言語で書かれており、外部依存なしの単一バイナリとしてコンパイルされるため、必要なメモリ使用量も非常に少なく抑えられています。Telegrafは多くのOSに対応しており、幅広いシステムパフォーマンスメトリクスを収集・転送できる便利な入力プラグインと出力プラグインを多数備えています。
Telegrafのインストールと設定は簡単ですが、我々はHG-CLIツールによってこのプロセスをさらに簡素化しました。任意のOSへツールをインストールし、TUIモードで実行してHosted Graphite APIキーを入力するだけで、素早くTelegrafを起動できます。
- HG-CLIツールをインストール:
curl -s "https://www.hostedgraphite.com/scripts/hg-cli/installer/" | sudo sh
- TUIモードで実行:
hg-cli tui
まだHosted Graphiteアカウントをお持ちでない場合は、無料トライアルへ登録してHosted Graphite APIキーを取得してください。
また、別のデータソースへメトリクスを転送したい場合は、別のTelegraf出力設定を構成することも可能です。
Lokiのインストールと設定(Linux)
最近の安定版であるLokiバージョン2.9.4をダウンロードします。
sudo wget https://github.com/grafana/loki/releases/download/v2.9.4/loki-linux-amd64.zip -O /usr/local/bin/loki.zip
unzipユーティリティを使ってパッケージを展開し、バイナリを準備します。
cd /usr/local/bin
sudo unzip loki.zip
sudo mv loki-linux-amd64 loki
sudo chmod +x loki
ログの取り込み、保存、提供方法をLokiへ指示するため、基本設定を行います。/etc/loki/loki-config.yaml に新しい設定ファイルを作成してください。
auth_enabled: false
server:
http_listen_port: 3100
ingester:
lifecycler:
ring:
kvstore:
store: inmemory
replication_factor: 1
schema_config:
configs:
- from: 2024-01-01
store: boltdb-shipper
object_store: filesystem
schema: v13
index:
prefix: index_
period: 24h
storage_config:
boltdb_shipper:
active_index_directory: /tmp/loki/index
cache_location: /tmp/loki/cache
cache_ttl: 24h
filesystem:
directory: /tmp/loki/chunks
limits_config:
max_entries_limit_per_query: 5000
table_manager:
retention_deletes_enabled: true
retention_period: 24h
compactor:
working_directory: /tmp/loki/compactor
設定ファイルを保存したら、以下のデータディレクトリを作成します。これらのディレクトリは設定ファイル内のパスと一致しており、Lokiは起動時に不足ディレクトリを自動作成しないため、この手順は必須です。
sudo mkdir -p /tmp/loki/index /tmp/loki/cache /tmp/loki/chunks /tmp/loki/compactor
sudo chown -R root:root /tmp/loki
Lokiの起動とテスト
Lokiを手動で起動し、エラーがないか出力を確認します。
sudo /usr/local/bin/loki -config.file=/etc/loki/loki-config.yaml
別のターミナルウィンドウで、Lokiが正常状態か確認します。
curl -s http://localhost:3100/ready
/metrics エンドポイントがメトリクスを返していることも確認します。
curl -s http://localhost:3100/metrics | head -n 25
また、Loki用のsystemd設定を作成すれば、バックグラウンドで自動起動させることもできます。ただし、この例ではLokiをそのまま実行した状態にして、別ターミナルで次の手順へ進めば問題ありません。
以下のログ取り込み負荷テストループをターミナルで実行し、Lokiをテストします。
while true; do
ts=$(($(date +%s%N)))
log="Stress log $(date) $(shuf -i 1-1000000 -n 1)"
curl -s -XPOST "http://localhost:3100/loki/api/v1/push" -H "Content-Type: application/json" \
-d '{"streams":[{"stream":{"job":"loki","level":"info"},"values":[["'"$ts"'", "'"$log"'"]]}]}' > /dev/null
sleep 0.005
done
TelegrafのPrometheus入力プラグインを設定
Telegrafには、多くの一般的な技術やサードパーティソースから幅広いデータを収集できる多数の入力プラグインがあります。この例では、Lokiが http://localhost:3100/metrics へメトリクスを公開しています。これらはPrometheus形式のメトリクスであり、Hosted Graphiteデータソースへ転送する際にGraphite形式へ変換する必要があります(Hosted Graphiteは前の手順で設定済みです)。
まず、Telegrafの設定ファイル(通常は /etc/telegraf/telegraf.conf にあります)を開き、以下のセクションを追加してください。
[[inputs.prometheus]]
urls = ["http://localhost:3100/metrics"]
metric_version = 2
name_prefix = "loki-performance."
その後、変更を保存し、以下のコマンドでTelegrafデーモンを実行します。これにより、出力内容から設定エラーがないか確認できます。
telegraf --config /etc/telegraf/telegraf.conf
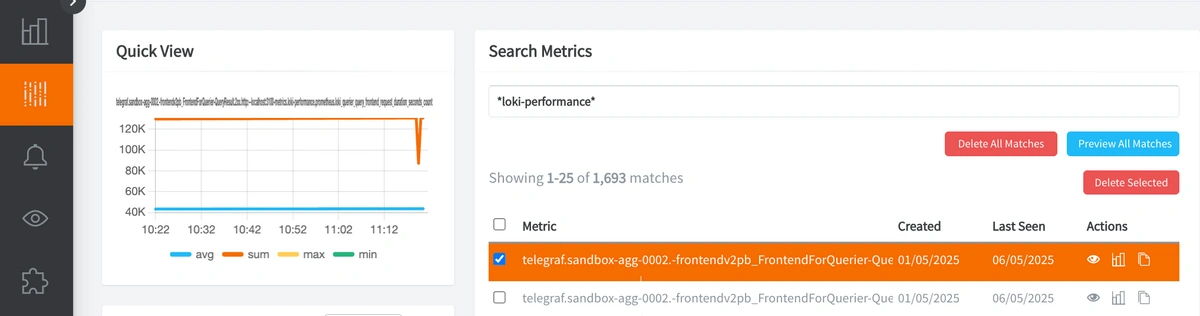
これで、Telegrafはローカルの /metrics エンドポイントをスクレイピングし、これらのメトリクスをHosted Graphiteアカウントへ転送するようになります。アプリのMetrics UI内で、loki-performance プレフィックス付きメトリクスを確認できます。
Prometheus入力プラグインに関する追加情報や設定オプションについては、公式GitHubリポジトリをご参照ください。
MetricFireを使ってカスタムダッシュボードとアラートを作成
MetricFireは、サーバー、データベース、ネットワーク、プロセス、デバイス、アプリケーションからメトリクスやデータを収集・可視化・分析できる監視プラットフォームです。MetricFireを利用することで、インフラ内の問題を簡単に特定し、リソースを最適化できます。MetricFireのHosted Graphiteは、監視ソリューションを自前でホスティングする負担を取り除き、より重要な作業に時間と集中力を使えるようにします。
Hosted Graphiteアカウントを作成し、上記の手順でTelegraf Agentをサーバーに設定すると、メトリクスはHosted Graphiteバックエンドへ転送・タイムスタンプ付与・集約されます。
-
メトリクスは次のようなGraphite形式で送信・保存されます: metric.name.path <numeric-value> <unix-timestamp>
-
このドット記法形式はツリー構造のデータ形式を提供するため、効率的なクエリ実行が可能です。
-
メトリクスはHosted Graphiteアカウント内に2年間保存され、これらを使ってカスタムアラートやGrafanaダッシュボードを作成できます。
Hosted Grafanaでカスタムダッシュボードを作成
Hosted Graphite UIで「Dashboards」に移動し、「+ New Dashboard」を選択して新しい可視化を作成します。
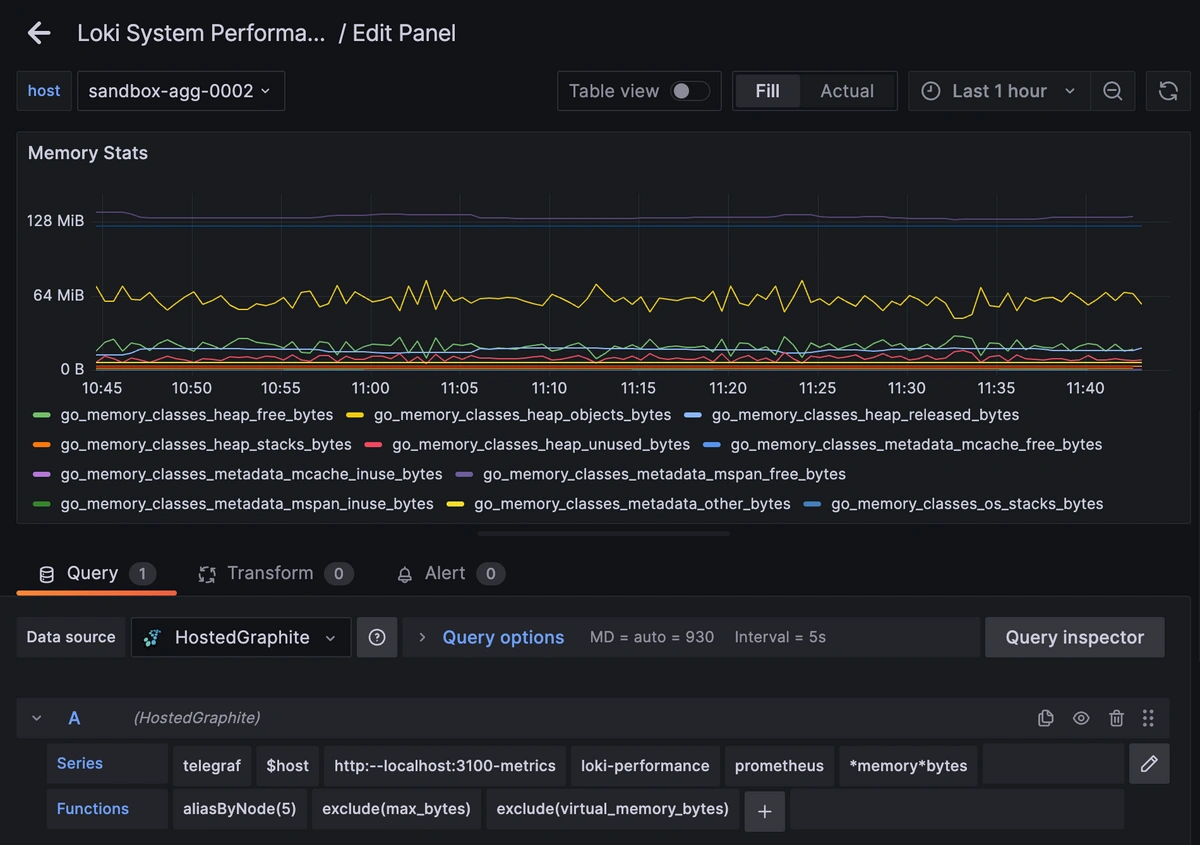
その後、編集モードに入り、Query UIを使ってGraphiteメトリクスパスを選択します(HGアカウント経由でGrafanaへアクセスしている場合、デフォルトのデータソースはHostedGraphiteバックエンドになります)。
HGデータソースは、指定したパスに一致するすべてのメトリクスを取得するためのワイルドカード(*)検索にも対応しています。
さらに、aliasByNode() を使ってメトリクス名を整理したり、exclude() を使って特定パターンを除外したりといったGraphite関数を適用できます。
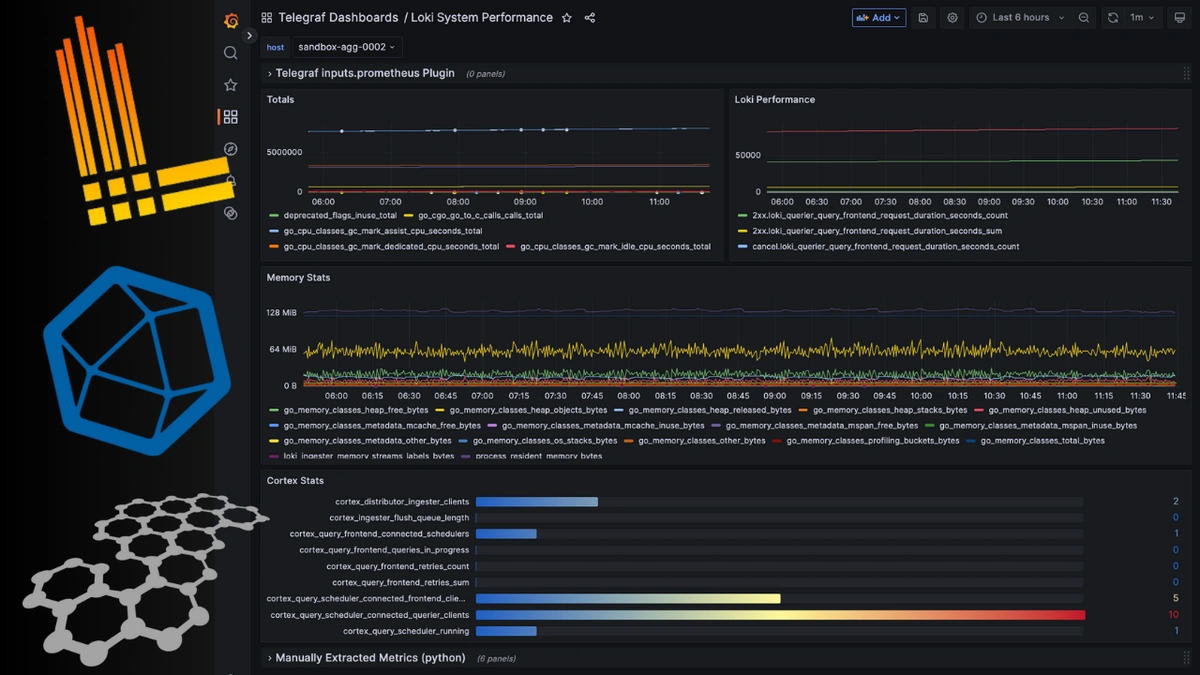
Grafanaには、さまざまな可視化オプション、表示設定、単位設定に加え、ダッシュボード変数やイベント注釈設定などの高度な機能も用意されています。
本番環境レベルのLoki Performanceダッシュボードは、次のような構成になります。
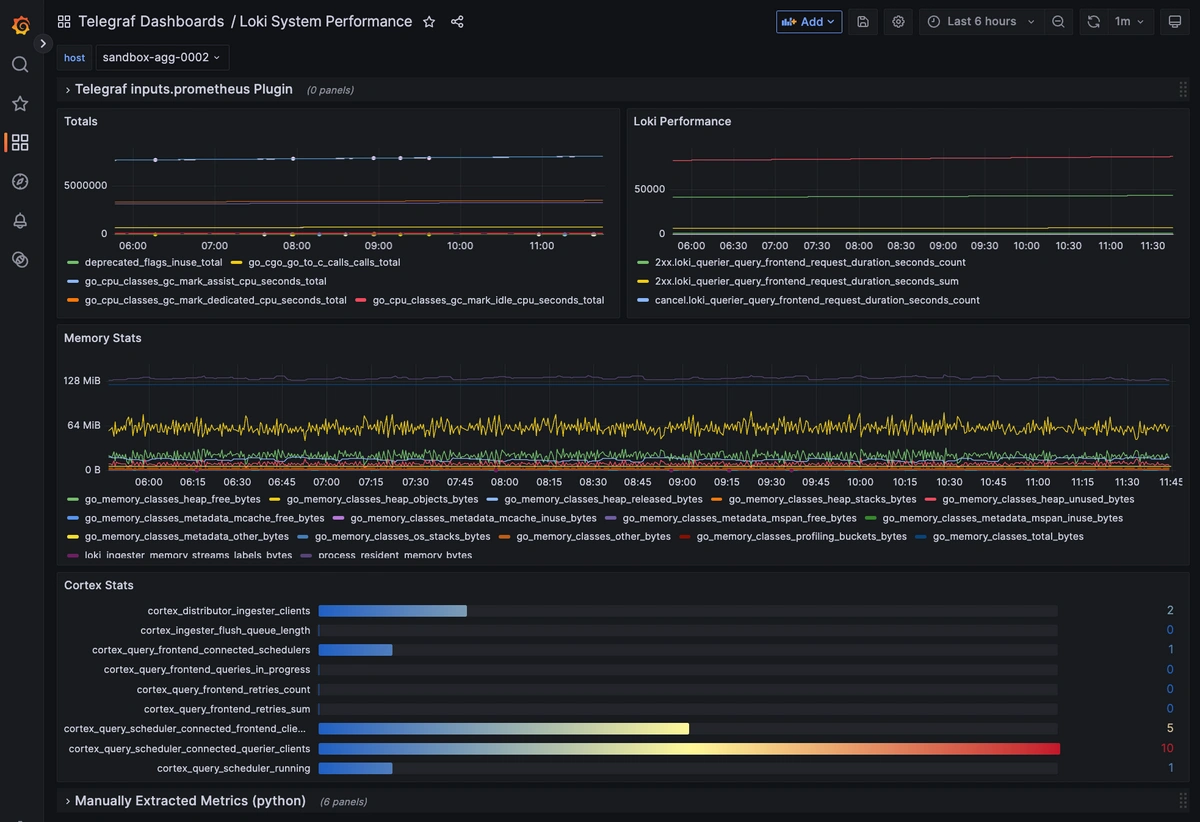
Graphiteアラートを作成
Hosted Graphite UIで「Alerts」に移動し「Graphite Alerts」を選択して、新しいアラートを作成します。アラート名を設定し、アラート対象メトリクスのクエリを入力し、このアラートの説明(任意)を追加します。
その後、「Alert Criteria」タブで閾値を設定し、通知チャネルを選択します。デフォルトの通知チャネルはHosted Graphiteアカウント登録時に使用したメールアドレスです。ただし、Slack、PagerDuty、Microsoft Teams、OpsGenie、カスタムWebhookなどのチャネルも簡単に設定できます。これにより、メトリクス値が期待範囲を外れた際に通知を受け取れます。
詳細については、Hosted Graphiteのドキュメントにある「Alerts」と「Notification Channels」をご参照ください。
まとめ
Lokiのネイティブ /metrics エンドポイントと、TelegrafのPrometheus入力プラグインを組み合わせることで、複雑なPrometheus環境を構築することなく、完全なLoki監視ソリューションを構築できます。これにより、Lokiの取り込みレート、クエリレイテンシ、キャッシュ効率、メモリ使用量をリアルタイムで可視化できます。このアプローチは、開発環境から本番環境までスムーズにスケールでき、さらにHosted Graphiteに組み込まれているアラート機能や可視化ツールを使って簡単に拡張することも可能です。
無料トライアルに登録して、今すぐインフラ監視を始めましょう。また、デモを予約して、監視ニーズについてMetricFireチームへ直接ご相談いただくことも可能です。