

Table of Contents
Great systems are not just built. They are monitored.
MetricFire runs Graphite and Grafana as a fully managed service for growing engineering teams, taking care of storage, scaling, and version updates so your team doesn't have to. Plans start at $19/month, billed per metric namespace rather than per host, and include engineer-staffed support. Integrations work natively with Heroku, AWS, Azure, and GCP, and data is stored with 3× redundancy in SOC2- and ISO:27001-certified data centres.
はじめに
前回の記事では、関連するシグナルをグループ化するためにワイルドカードクエリを使用して、サービスレベルのアラートを設定しました。このアプローチにより、アラートが個々のメトリクスではなくシステム全体を反映するようになり、アラートのノイズを低減できます。
しかし、適切にグループ化されたアラートであっても、感度が過剰になる可能性があります。単一のシグナルがしきい値を超えたからといって、必ずしも実際の問題が発生しているとは限りません。システムは複雑であり、個々のシグナルは通常時でも変動することが多いため、ここで複合アラートが役立ちます。複合アラートでは、シグナルを個別に評価するのではなく、サービス全体の挙動を反映した条件を定義することができます。
本記事では、サービスおよびシグナルモデルを基盤として、条件分岐ロジックを導入します。AND(論理積)およびOR(論理和)の関係を使用することで、孤立した異常ではなく、意味のあるシステムの挙動を捉えるようなアラートを設定することが可能になります。
1: 単一条件アラートが不十分な理由
アラートが適切にグループ化されていたとしても、単一条件のしきい値ベースアラートは依然としてノイズを生み出す可能性があります。例として、これまで使用してきたロードバランシングサービスのメトリクスを考えてみましょう。
<host>.lb.forwarder.requests.rate
<host>.lb.worker.requests.rate
<host>.lb.queue.depth.value
<host>.lb.latency.p95.value
<host>.lb.health.status.value
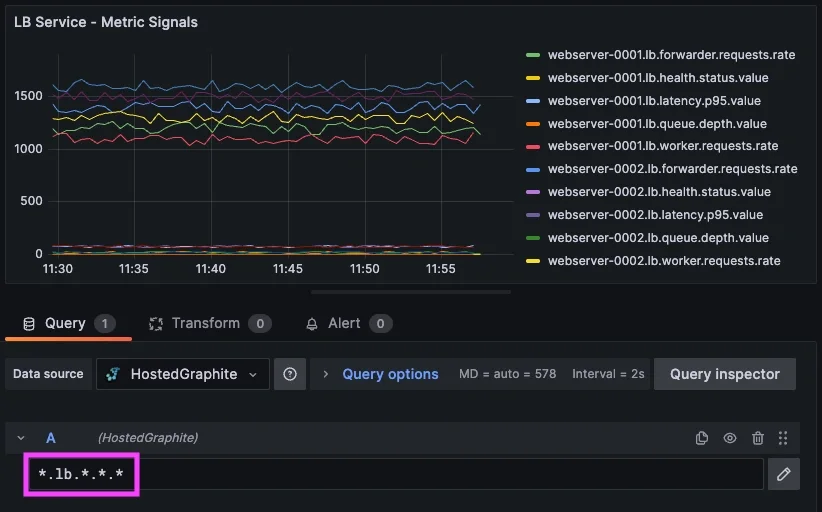
これらのメトリクスシグナルはそれぞれ有用な情報を提供しますが、単独では必ずしもサービス障害を示すとは限りません。
例えば:
- latency は、トラフィック急増時に一時的にスパイクする場合があります
- queue depth は、通常の負荷変動中でも増加する場合があります
- request rate は、トラフィック分散の偏りによって一時的に低下することがあります
もしこれらの条件のいずれか1つだけでアラートを発火させると、システムが正常動作している場合でもアラートが発生する可能性があります。そして、これは別種類のアラートノイズにつながります。重複アラートではなく、「技術的には正しいが、実際には対処しづらいアラート」が増えるのです。つまり、本質的な問題はメトリクスのグループ化ではありません。問題は「コンテキスト」にあります。
2: コンポジットアラートの活用
コンポジットアラートでは、単一のしきい値ではなく、複数条件に基づいてアラートを定義できます。
つまり、次のように考える代わりに:
「1つのメトリクスがしきい値を超えたか?」
次のように考えられるようになります:
「システムは、実際の問題を示すような動作をしているか?」
これは、AND や OR(&& ||)のような論理条件を使って実現されます。例えば、ロードバランシングサービス用のコンポジットアラートは次のように定義できます。
IF <host>.lb.forwarder.requests.rate < X AND <host>.lb.queue.depth.value > X
OR <host>.lb.latency.p95.value > X
OR <host>.lb.health.status.value < 1
THEN trigger an LB-service alert
これは、サービスが障害状態になる複数のパターンを、1つのアラート内で定義していることになります。
各条件は1つのシグナルを表しており、それらを組み合わせることで、障害時のサービス挙動を定義しています。
ORロジックとANDロジックの違いを理解する
「OR」と「AND」の選択は重要です。
「OR」ロジックを使用する場合:これらの条件のいずれかが満たされた場合にアラートをトリガーします。
これは、サービス内のさまざまな種類の障害を検出するのに役立ちます。例えば、サービスはレイテンシ、可用性、またはスループットの問題によって障害が発生する可能性があり、それぞれが独立してアラートをトリガーする必要があります。
「AND」ロジックを使用する場合:複数の条件が同時に真である場合にのみアラートをトリガーします。
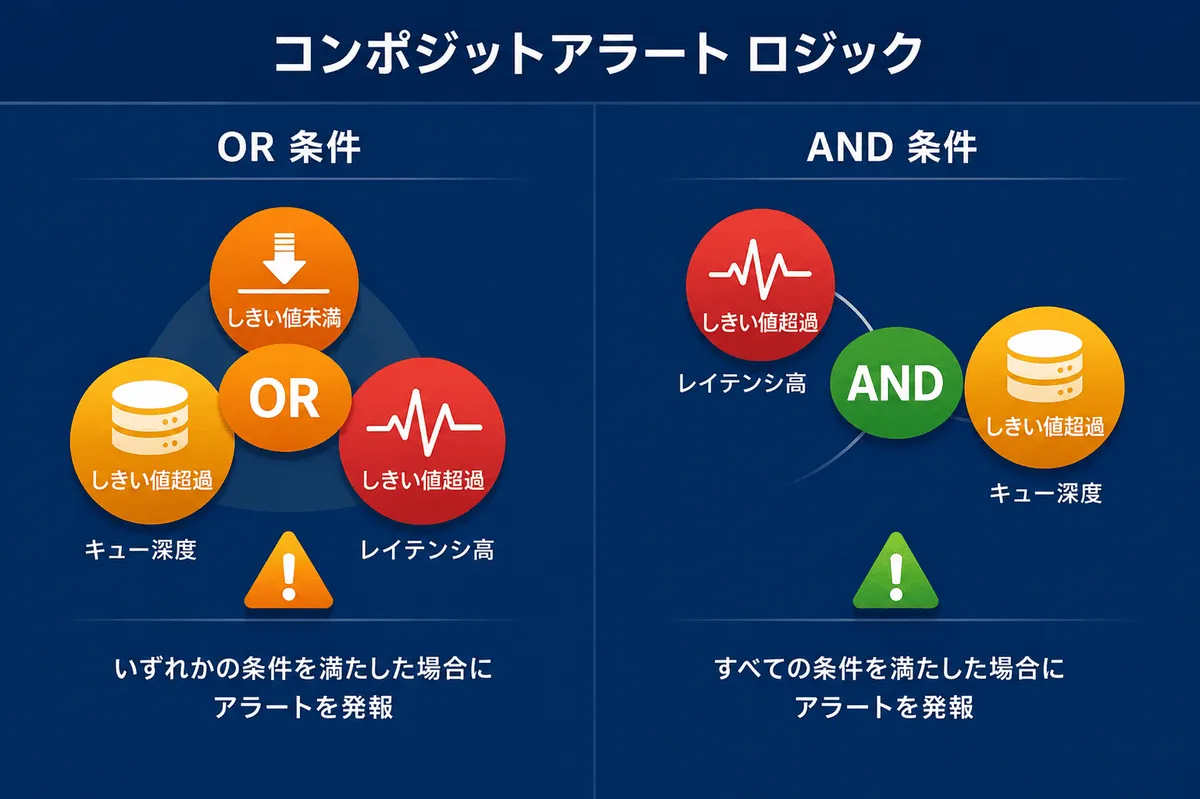
これにより、レイテンシの急上昇が、実際の問題である可能性が高い「キューの深さ」の増加を伴う場合にのみ、アラートがトリガーされるようになります。実際には、ほとんどの複合アラートでは、誤検知を減らすためにAND/ORロジックの両方を組み合わせて使用しています。
3: シグナルによるサービス挙動の定義
ここで、サービスとシグナルのモデルが最も有効になります。各サービスは、その挙動の異なる側面を表す複数のシグナルを公開しているためです。あるシグナルはスループットやトラフィックフローを表し、別のシグナルはレイテンシ、飽和状態、可用性、または全体的なシステム健全性を表します。
コンポジットアラートでは、これらのシグナルを条件付きロジックによってまとめて評価できます。これにより、孤立したメトリクス変化へ反応するのではなく、アラートが「意味のあるサービス挙動」を表現できるようになります。そして、単一アラート定義の中で複数の障害シナリオを扱えるようになります。ロードバランシングサービスの例では、現実的なコンポジットアラートは次のようになります。
IF (*.lb.latency.p95.value > 120 AND *.lb.queue.depth.value > 75)
OR (*.lb.health.status.value < 1)
OR (*.lb.forwarder.requests.rate < 1000)
THEN send an LB-service alert.
このアプローチにより、単一のアラートでロードバランシングサービス全体の状態を表現でき、同時に下位シグナルが「なぜアラートが発火したのか」を説明します。
このパターンを他サービスへ適用する
このパターンは、他のサービス(api、jobs、db など)にも自然に拡張できます。
APIレイヤーの場合:
IF (*.api.latency.p95.value > X AND *.api.errors.total.rate > X)
OR (*.api.workers.active.value > X)
THEN send an API-service alert
DBレイヤーの場合:
IF (*.db.latency.p95.value > X AND *.db.connections.active.value > X)
OR (*.db.writes.total.rate < X)
THEN send a DB-service alert
各サービスは、自身のシグナルに基づいて独自の挙動を定義しますが、構造自体は同じです。この一貫性によって、複雑性を増やさずに、システム全体へアラートをスケールしやすくなります。
コンポジットアラートで問題シグナルのみを返す
コンポジットアラートでも、グループ化されたワイルドカード(*)セットから「問題を起こしているメトリクスのみ」を返す利点があります。コンポジットアラートが発火した場合、条件を満たしたシグナルだけが返されます。
例えば、LB-service の例で、latency > threshold AND queue depth > threshold の条件が満たされた場合、問題メトリクス一覧は次のようになる可能性があります。
- webserver-0002.lb.latency.p95.value = 320
- webserver-0002.lb.queue.depth.value = 85
別条件、worker requests < threshold AND forwarded requests < threshold で発火した場合は、次のようになります。
- webserver-0001.lb.worker.requests.rate = 825
- webserver-0001.lb.forwarder.requests.rate = 780
アラートは、サービスごとに個別のアラートを定義するのではなく、システム全体にわたるサービスの健全性を監視するためにも使用できます。例として、次のようなグループ化されたワイルドカードクエリがあります:*.*.health.status.value
このアラートクエリは、全てのサービスおよびホストにわたる健全性シグナルを評価し、いずれかのサービスがX分間「不健全」な状態を報告した際にトリガーされ、影響を受けたメトリックシグナルを返します。
- webserver-0003.lb.health.status.value = 0
- db-0001.db.health.status.value = 0
このモデルにより、アラートはシステムの実際の理解や運用方法と整合性を保つことができます。アラートでサービスの状態を表し、シグナルでその背景となるコンテキストを提供することで、明瞭さを損なうことなく、検知と診断を分離します。その結果、アラートが影響を伝え、シグナルが原因を明らかにするという、より直感的でスケーラブルなアプローチが実現されます。
サービスシグナルとホストエージェントメトリクスの組み合わせ
ここまでの記事例では、レイテンシ、スループット、健全性などのカスタムサービスレベルシグナルに焦点を当ててきました。これらはサービス挙動を説明しますが、「なぜ挙動が変化しているのか」までは必ずしも説明できません。なぜなら、サービス劣化は基盤システム状態の影響を受けることが多いためです。
例えば、Telegrafのようなエージェントによって収集される:
telegraf.<host>.mem.used_percent
のようなメトリクスを、サービスレベルシグナルと組み合わせることで、重要なコンテキストを追加できます。
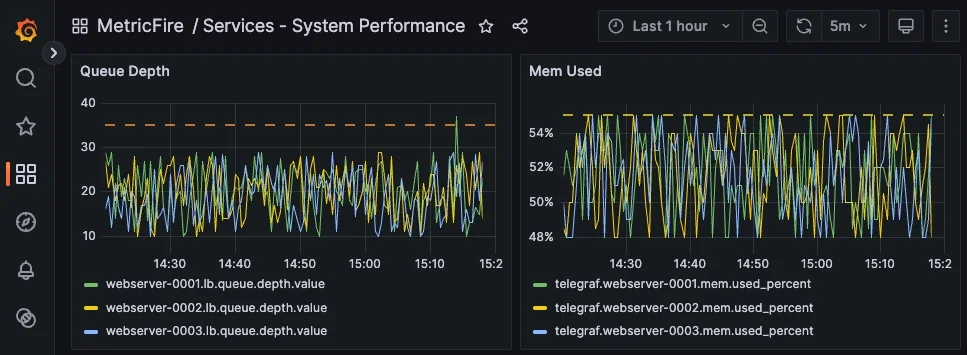
コンポジットアラートには、あらゆる種類のメトリクスを含めることが可能です。例えば、Queue Depth が高いかつホストのメモリ使用率も高い場合にアラートを発火させることができます。これにより、アプリケーション問題なのか、リソース制約なのかを区別しやすくなり、アラートはより有用で対応しやすいものになります。
4: MetricFireのHosted Graphiteでこれらの概念を適用
Hosted Graphiteでは、コンポジットアラートをAlerts UI内で直接定義できます。これにより、複数の個別ルールへ依存せずに、複雑なアラートロジックをより簡単に構築・管理できます。
各アラートは1つ以上のメトリクスクエリで構成でき、それらのクエリへ条件を適用し、論理関係によって条件同士をどのように評価するかを定義できます。ワイルドカードクエリ(*)は引き続きサービスアラートのスコープ定義に使用され、コンポジットロジックが基盤シグナルをどのように解釈するかを決定します。
現在、コンポジットアラートはHosted Graphite Alerts APIを通じてサポートされています。コンポジットアラート用ユーザーインターフェースも現在開発中で、近日公開予定です。
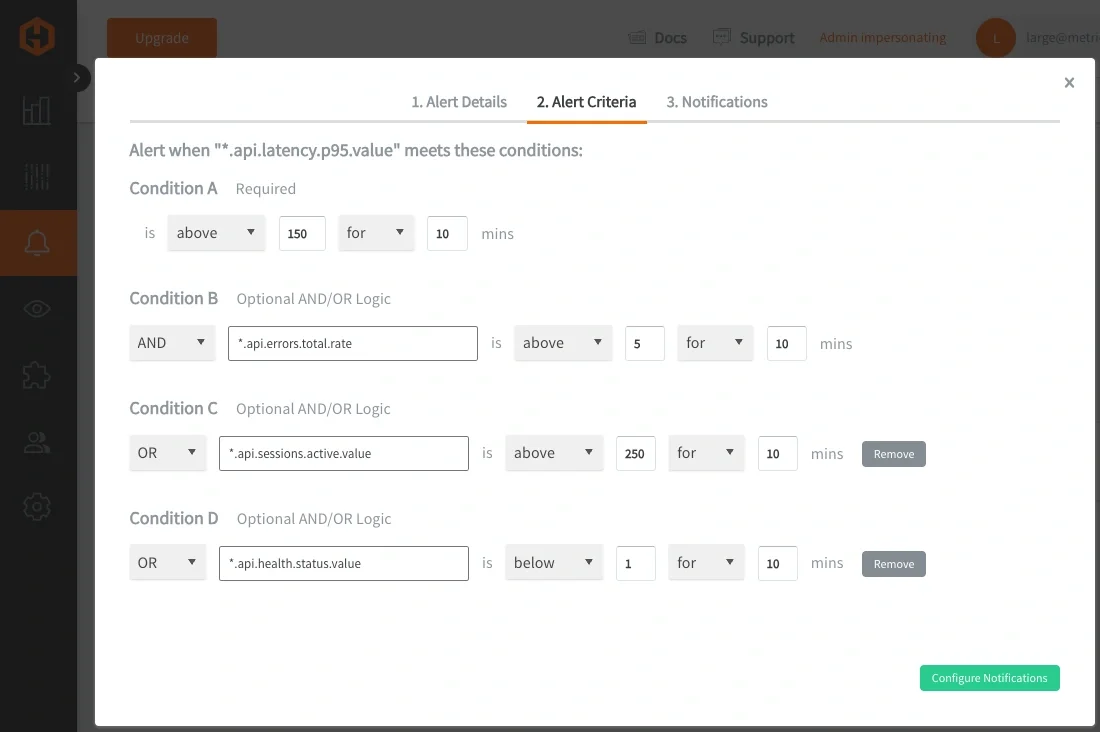
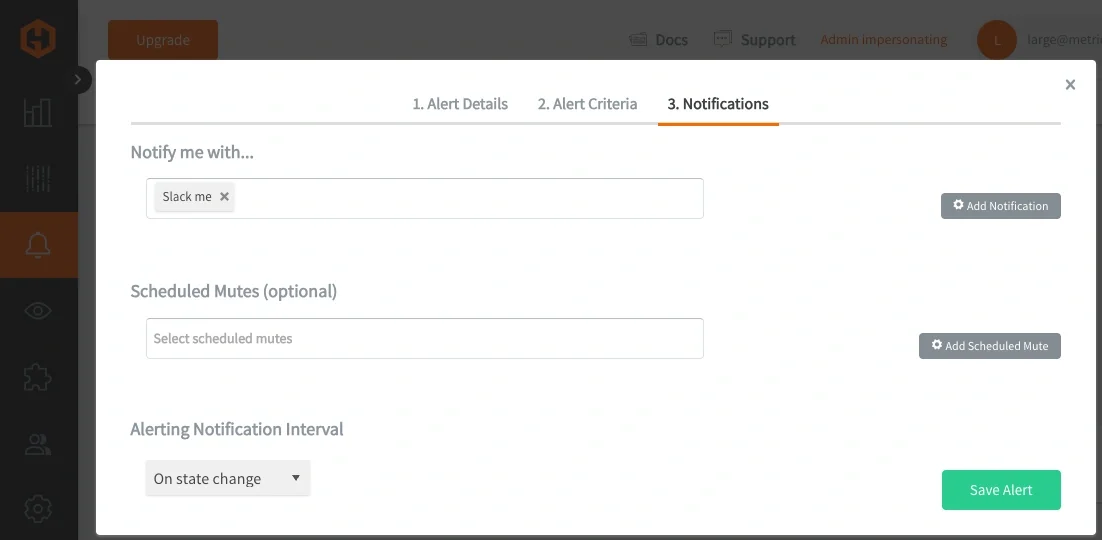
このアプローチにより、関連条件を単一で一貫性のある定義へ統合できるため、必要なアラートルール数を削減できます。また、一時的または孤立した変化へ反応するのではなく、「意味のあるパターン」が現れた場合のみアラートが発火するため、シグナル品質も向上します。時間の経過とともに、これはサービスが実際に負荷下でどのように動作しているかをより正確に表現する、安定性と保守性の高いアラートシステムにつながります。
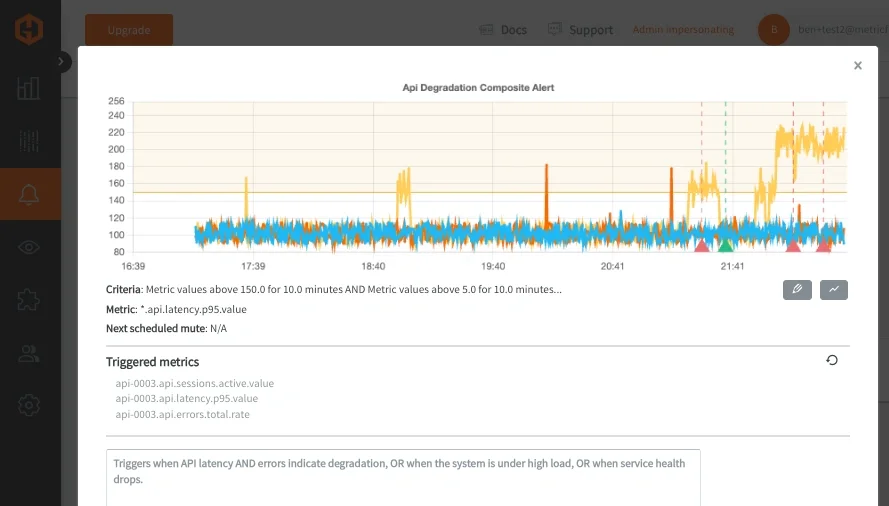
アラート発火後は、Email、Slack、PagerDuty、MSTeams、Webhookなどの標準通知チャネルへルーティングできます。また、グループ化ワイルドカードクエリから、問題を起こしている全メトリクスが一覧表示されます。
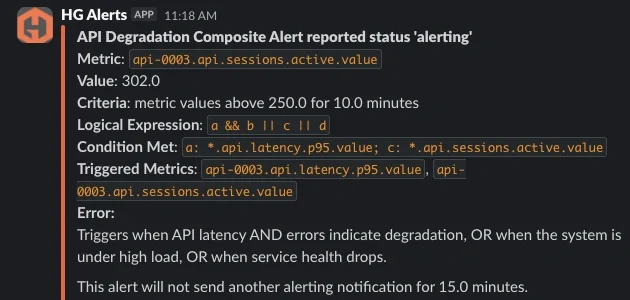
更新された通知フォーマットにより、インシデント発生時のコンポジットアラート解釈が大幅に容易になります。各トリガーメトリクスが、「どの条件が true になったか」と関連付けられるようになったためです。
以前のようにグループ化ワイルドカードクエリだけを見るのではなく、エンジニアは:
- アラートロジックのどの部分が満たされたのか
- どの基盤シグナルがアラートへ寄与したのか
を即座に把握できます。
例えば:
- 条件 A = APIレイテンシ高騰
- 条件 C = アクティブセッション増加
を表している場合、通知には:
- 満たされた論理条件
- それに関連する問題メトリクス
の両方が表示されます。
これにより、トリアージ中の運用コンテキストが大幅に明確になり、「なぜアラートが発火したのか」を理解するための手動調査量を削減できます。
MetricFireでは、自社アラート基盤内でまさに同じ問題に直面しました。具体的には、受信トラフィックを処理するルーティングレイヤー内です。そのレイヤー内では複数コンポーネントが同時に障害を起こす可能性があり、それぞれが個別アラートを生成していました。その結果、実際には同一原因を指しているにもかかわらず、大量のアラートクラスターが発生していました。
アラート構造を、より一貫性のある「サービス&シグナル階層」に再編成した後、これらコンポーネントを単一の「サービスレベル」アラート下へグループ化できるようになりました。これにより、サービス全体の健全性評価、および障害発生時にどのシグナルが原因だったかの特定が可能になりました。MetricFire内部のアラート基盤において、どのようにこれら概念を適用し、本番トラフィックルーティング層のノイズや冗長アラートを削減したのかご覧いただけます。
Hosted Graphite上では、この構造はダッシュボードやアラート構築方法へ直接反映されます。クエリは予測可能なパス構造へ依存するため、よりシンプルになります。また、アラートルールは個別メトリクスへ紐づくのではなく、サービス層全体に対して機能するようになります。
まとめ
サービスレベルアラートは、関連するシグナルを単一のシステムビューへまとめることで、ノイズを削減します。コンポジットアラートは、その基盤の上に構築されるものであり、それらシグナルがどのように相互作用するかを定義します。これにより、アラートは孤立したメトリクス変化ではなく、「意味のあるシステム挙動」を反映できるようになります。
システムの複雑性が増すにつれて、この変化は不可欠になります。個別しきい値へ反応するのではなく、アラートが実際のサービス状態を表現するようになることで、アラートへの信頼性が高まり、対応も迅速になります。これは、誤検知を減らし、シグナルの明確性を向上させ、検知から診断までの時間短縮につながります。
これらを総合すると、メトリクス構造、ワイルドカードグループ化、そしてコンポジットロジックは、完全なGraphiteアラートモデルを形成します。それは、システム成長に合わせてスケールし、エンジニアが内部サービスをどのように捉えているかと一致し、最終的にはメトリクスデータを実用的なインサイトへ変換するモデルです。
