

Table of Contents
Great systems are not just built. They are monitored.
MetricFire runs Graphite and Grafana as a fully managed service for growing engineering teams, taking care of storage, scaling, and version updates so your team doesn't have to. Plans start at $19/month, billed per metric namespace rather than per host, and include engineer-staffed support. Integrations work natively with Heroku, AWS, Azure, and GCP, and data is stored with 3× redundancy in SOC2- and ISO:27001-certified data centres.
はじめに
ほとんどのアラートシステムは、個々のメトリクスに対してしきい値を定義することから始まります。これにより、値がそのしきい値を超えた際にアラートがトリガーされます。このアプローチはシステムが小規模な場合は問題なく機能しますが、サービスが拡大し、より多くのシグナルが生成されるようになると、管理が困難になります。単一のサービスが、関連する複数のメトリクス(指標)を生成することはよくあります。例えば、スループット、レイテンシ、キューの深さ、ヘルス状態などはすべて、同じシステムの異なる側面を表している可能性があります。これらの各コンポーネントに対して個別にアラートを設定すると、重複が生じるだけでなく、より重要な点として、それらを結びつける文脈が失われてしまいます。
本シリーズの前回記事では、メトリクスの階層構造の中でサービスとそのシグナルが明確に定義されるよう、メトリクスの構造化に焦点を当てました。
本記事では、その基礎を土台として、Graphiteのワイルドカードクエリ(*)を使用し、関連するメトリクス信号を意味のあるアラート定義にグループ化する方法を解説します。メトリクスごとにアラートを作成するのではなく、サービスとその内部コンポーネントを中心にアラートを定義し、アラートが発火した際に原因となる具体的なメトリクスを特定します。
1: メトリクス単位のアラートがノイズを生む理由
前回の記事のロードバランシング例を考えてみましょう。この例では、トラフィック処理状況を表す複数のシグナルが公開されています。
<host>.lb.forwarder.requests.rate
<host>.lb.worker.requests.rate
<host>.lb.queue.depth.value
<host>.lb.health.status.value
<host>.lb.latency.p95.value
これらのメトリクスはそれぞれ単体では有効ですが、すべて同じシステムの一部です。では、トラフィックが滞留し始める障害シナリオを想像してみてください。キューの深さが増加し、レイテンシが上昇し、リクエストスループットが低下するかもしれません。もしメトリクスごとにアラートが定義されている場合、これらのシグナルはそれぞれ独立して発火します。その結果、1つの問題に対して複数のアラートが生成され、それぞれがサービス全体の文脈を欠いた状態になります。
ここでアラートノイズが問題になり始めます。問題なのはシグナルそのものではなく、アラート定義時にそれらをどのようにグループ化しているかにあるのです。
2: ワイルドカードを使った意味のあるアラートグループ化
ワイルドカードクエリを使うことで、メトリクスパス内の位置に基づいて関連メトリクスをグループ化できます。重要なのは、システムをどのように捉えたいかに合わせてメトリクスをグループ化することです。そのため、サービス内のすべてのシグナルに対して一度にアラートを設定しようとするよりも、シグナルタイプごとにグループ化した方が実用的な場合が多くあります。
例えば、以下のようにする代わりに:*.lb.*.*.*
(これは単位や挙動が大きく異なるメトリクスを含みます)
より実用的なグループ化は次のようになります:*.lb.*.requests.rate
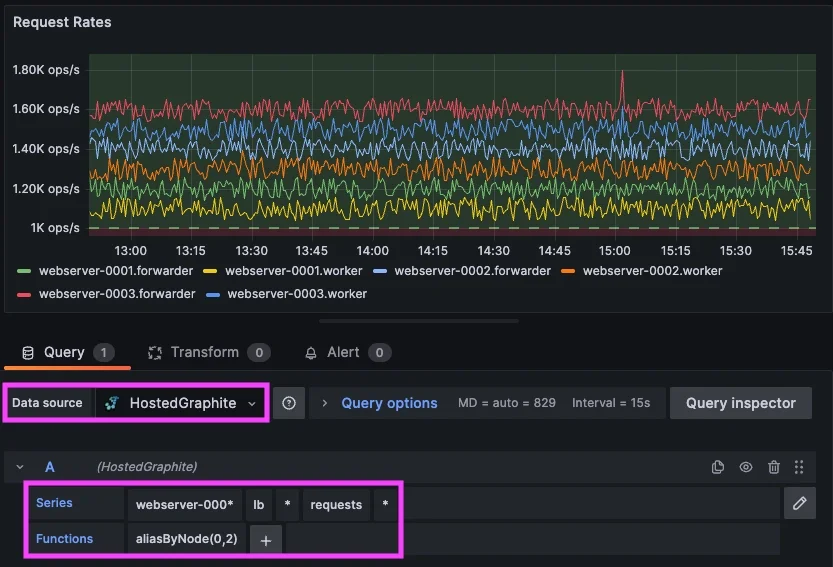
このクエリは、すべてのロードバランサーホスト/コンポーネントにおけるリクエストスループットメトリクスを取得します。そして、これらのメトリクスは同じ単位と意味を共有しているため、まとめて評価できます。これにより、サービス全体のリクエスト処理を表す単一のアラートを定義できます。
例えば、次のようなアラート条件を設定できます:
「ロードバランサーのリクエストレートが1000 req/secを下回った場合にアラートを発火する」
このアラートが発火した場合、それは単一メトリクスの問題ではなく、サービス全体のトラフィック処理能力の低下を意味します。
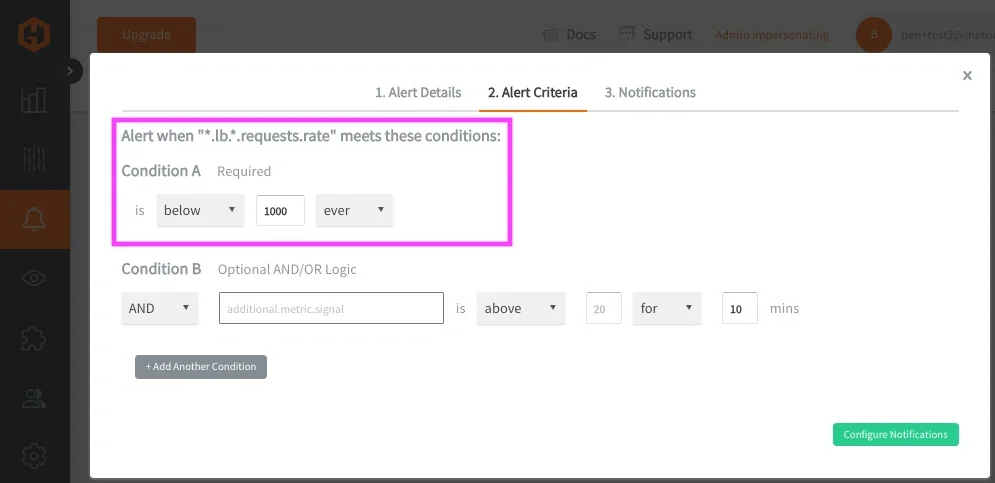
ほとんどの場合、これらのワイルドカードアラートは、一致した各時系列を個別に評価します。つまり、1つの劣化したシグナルだけでアラートが発火し、その問題メトリクスが特定されます。このパターンは、複数のサービスやシグナルタイプに適用できます。
- すべてのホスト/サービスにおけるレイテンシ:*.*.latency.p95.value
- ホスト全体のメモリ使用率:telegraf.*.mem.used_percent
- すべてのホスト/サービスにおけるヘルスチェック:*.*.health.status.value
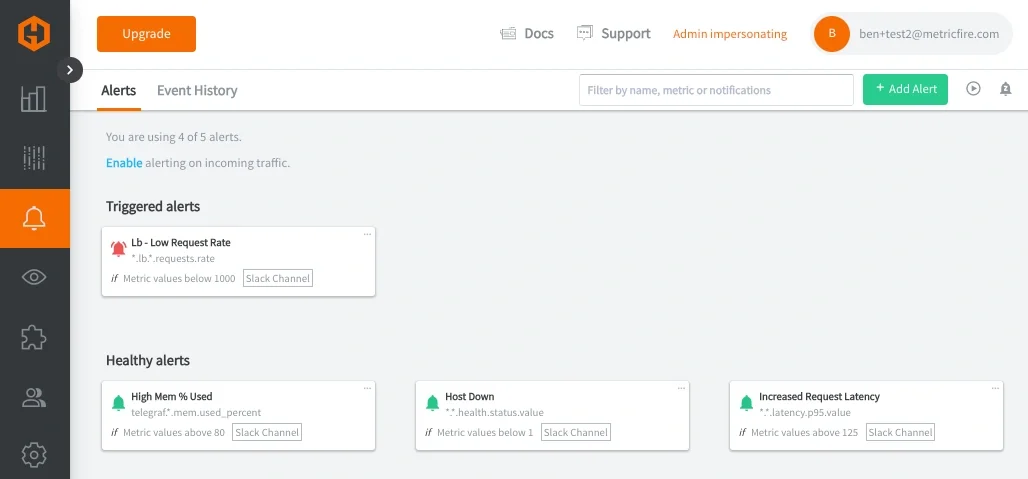
これらのアラートクエリはそれぞれ、サービス内で動作する個々のコンポーネントではなく、システムサービスの振る舞いに基づいた意味のあるグループ化を定義しています。
上記の例でTelegrafメトリクスが含まれていたことに気づきましたか?TelegrafやOpenTelemetryのようなエージェントをサーバーフリート全体に導入することは、システムレベルのパフォーマンスメトリクスを任意のデータバックエンドへ転送する最も簡単で迅速な方法の一つです。
なぜメトリクス構造が重要なのか
これらのグループ化がうまく機能するのは、メトリクス構造に一貫性があるためです。メトリクスパス内の各セグメントには定義された意味があります。
<host>.<service>.<signal>.<metric>.<stat>
この構造により、ワイルドカードクエリは、曖昧さなくサービス、シグナル、測定タイプといった特定の次元を対象にできます。
システムメトリクスを常に同じ深さで維持することが必ずしも可能とは限りません。しかし、可能な場合はそうすることで、アラートグループ化の信頼性が高まり、アラート定義の保守も容易になります。この概念の詳細については、「メトリクス命名ベストプラクティス」に関する関連記事をご覧ください。
3: このパターンを複数サービスへ拡張
ロードバランシング層は、シグナルが理解しやすいため良い出発点ですが、このパターンは複数サービスへ適用することでさらに価値を発揮します。
一般的なシステムでは、リクエストは複数のレイヤーを通過します。この例では、ロードバランサー、DreamFactoryのような自己ホストAPIプラットフォーム、バックグラウンドジョブ処理、データベース向けのメトリクスを定義しました。それぞれのサービスは異なるシグナルセットを公開していますが、すべて似た構造に従っており、同じアプローチでグループ化できます。
APIレイヤーでは、リクエストスループットとレイテンシが主要なシグナルになります。
*.api.*.requests.rate
*.*.latency.p95.value
バックグラウンドジョブ処理では、キューの深さとスループットがシステム挙動を表します。
*.jobs.queue.depth.value
*.jobs.*.processed.total.rate
データベースでは、クエリレートとレイテンシが負荷とパフォーマンスを示します:
*.db.*.queries.total.rate
*.db.*.latency.p95.value
そして、すべてのサービス横断で、Telegrafのようなエージェントから取得されるシステムパフォーマンスメトリクスが、可用性やリソース使用率の一貫したビューを提供します:
telegraf.*.system.uptime
telegraf.*.cpu-total.cpu.usage_system
telegraf.*.mem.used_percent
telegraf.*.processes.running
これらのクエリはそれぞれ、エンジニアがシステムをどのように捉えるかに基づいてメトリクスをグループ化しています。個々の時系列に注目するのではなく、サービス全体やシグナルタイプ全体の挙動を評価しているのです。これらのアラートを設定すると、サービス間で一貫した動作をします。レイテンシアラートを各レイヤーごとに再定義する必要はありません。ヘルスアラートをホストごとに複製する必要もありません。同じワイルドカードパターンを適用でき、アラート出力によって影響を受けているサービスとホストが特定されます。
ここで前回の記事の構造が重要になります。各メトリクスが同じ階層構造に従っているため、追加の複雑さを導入することなく、このアプローチをシステム全体へ拡張できます。この段階になると、ダッシュボードとアラートが連携し始めます。Grafanaでは、各サービスをスループット、レイテンシ、キャパシティ用パネルで可視化できます。そしてアラート側では、それらと同じグループ化がサービスレベルアラートの基盤になります。その結果、次のような監視モデルが実現します。
- ダッシュボードは、サービスが時間経過とともにどのように振る舞うかを表示する
- アラートは、その挙動がしきい値を超えたときに通知する
- 返されるメトリクスが、原因となっている具体的なシグナルを特定する
これをより具体的にすると、以下のダッシュボード例は、複数ホスト/サービスにまたがるこれらのグループ化が実際にどのように見えるかを示しています。
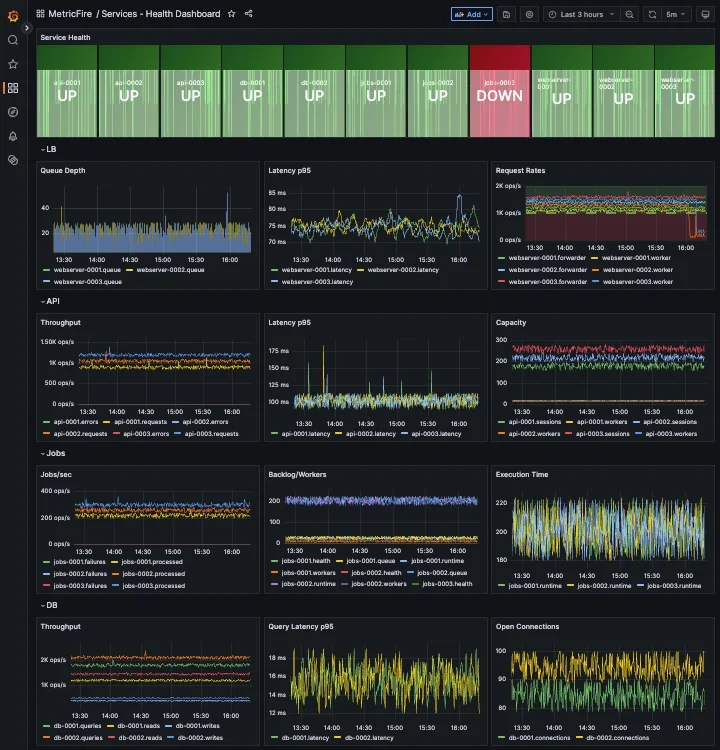
これにより、コンテキストを切り替えたり複数アラートを手動で関連付けたりすることなく、検知から原因特定へ移行しやすくなります。
4: MetricFireのHosted Graphiteでこれらの概念を適用
Hosted Graphiteでは、このアプローチがアラート設定方法に直接対応しています。
ワイルドカードクエリは、特定サービスなのか、複数サービスにまたがるシグナルタイプなのかといった、アラートの対象範囲を定義するために使用されます。アラート条件はこれらのグループ化されたメトリクスに適用され、発火時には定義されたしきい値を超えたメトリクスのみが返されます。これにより、必要なアラートルール数を削減でき、アラート発生時の解釈もしやすくなります。具体的には、次のような形になります。
- LBスループット用のアラート1つ
- 全サービス(api、cache、DB)にまたがるレイテンシ用アラート1つ
- 全ホストにまたがるメモリ使用率用アラート1つ
- サービスヘルス用アラート1つ
つまり、数十個の個別アラートを管理する代わりに、システムの実際の振る舞いを反映した少数のグループ化アラートを定義することになります。
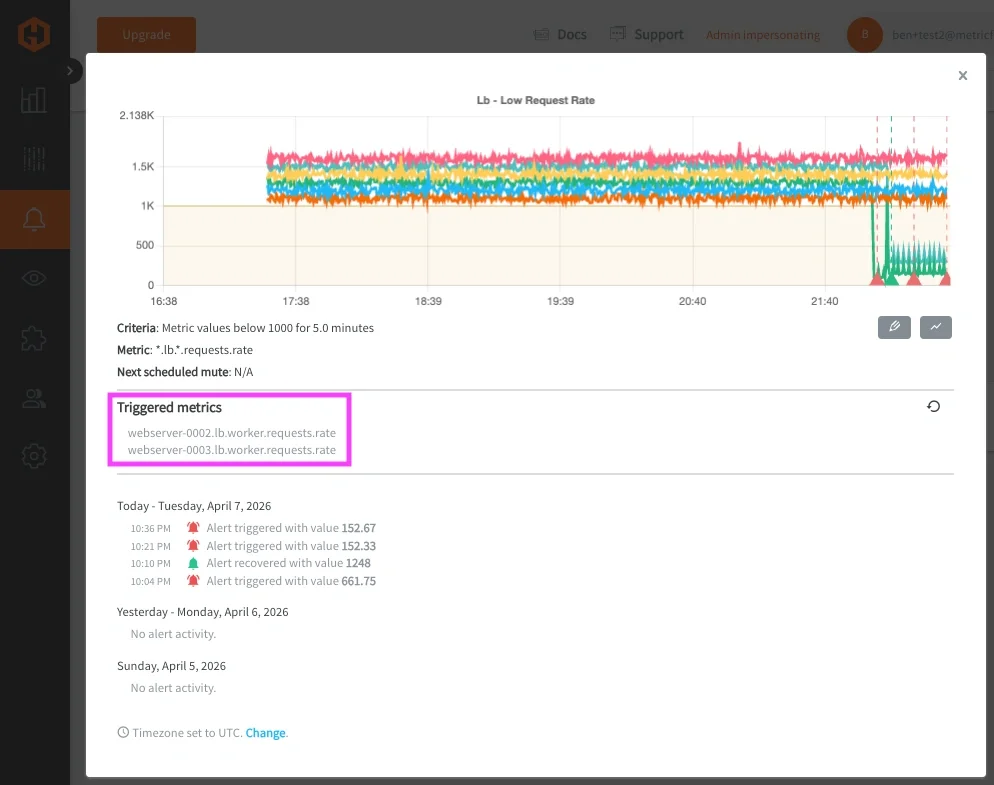
一度定義すれば、これらのアラートはメール、Slack、PagerDuty、MSTeams、Webhookなどの通知チャネルへルーティングできます。通知方法自体は変わりませんが、シグナル品質は大幅に向上します。
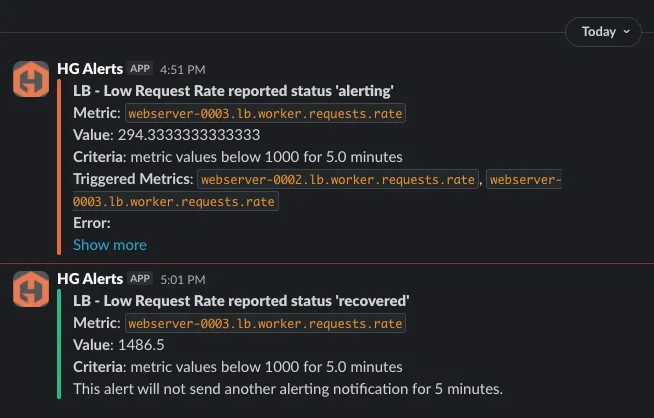
MetricFireでは、自社のアラートインフラ内、特に受信トラフィックを処理するルーティングレイヤーにおいて、まさにこの問題に直面しました。このレイヤー内の複数コンポーネントが同時に障害を起こす可能性があり、それぞれが独自のアラートを生成していたため、同じ根本原因を指しているアラート群が発生していました。
アラート構造を、より一貫したサービス/シグナル階層へ再編成した結果、それらのコンポーネントを単一の「サービスレベル」アラート配下にグループ化できるようになりました。これにより、サービス全体の健全性を評価しつつ、問題発生時にはどのシグナルが原因だったかを特定できるようになりました。MetricFire内部のアラートインフラにおいて、これらと同じ概念をどのように適用し、本番トラフィックルーティングレイヤーのノイズや重複アラートを削減したのかをご覧ください。
Hosted Graphiteで作業する場合、この構造はダッシュボードやアラート構築方法に直接反映されます。クエリは予測可能なパス構造に依存するためシンプルになり、アラートルールは個別メトリクスに縛られることなく、サービス全体を対象に動作できます。次回の記事では、ターゲットを絞ったワイルドカードグループ化による効率的なアラート構築方法と、Composite Alertsを使用した条件付きAND/ORロジックの追加方法について詳しく解説します。
まとめ
メトリクス単位のアラートは、各シグナルをサービスとの関連性を考慮せずに個別に扱うため、アラートが過剰になりがちです。
ワイルドカードクエリを使用してGraphiteのメトリクスをグループ化することで、スループット、レイテンシ、ヘルス状態といった意味のある次元に基づいてアラートを定義できます。問題のあるメトリクスのみを抽出することで、何が変化したのかを迅速に把握するために必要な文脈が得られるのです。その結果、アラートの数が減り、シグナルが明確になり、対応の迅速化が図れます。
