Table of Contents
Great systems are not just built. They are monitored.
MetricFire runs Graphite and Grafana as a fully managed service for growing engineering teams, taking care of storage, scaling, and version updates so your team doesn't have to. Plans start at $19/month, billed per metric namespace rather than per host, and include engineer-staffed support. Integrations work natively with Heroku, AWS, Azure, and GCP, and data is stored with 3× redundancy in SOC2- and ISO:27001-certified data centres.
はじめに
ほとんどのチームは、実際の原因に気づくより前に、アラートノイズの問題へ直面します。
最初はアラート設定の問題に見えます。アラートが多すぎる、しきい値調整が不十分、ワイルドカードクエリが想定以上のパスへ一致してしまう、といった状態です。もちろん、アラートルールを調整したり、ミュートしたりすることはできます。しかし、根本的な問題はもっと前の段階、つまり「メトリクス名を定義する時点」から始まっていることがほとんどです。
Graphiteは、サービス、コンポーネント、システム境界を理解しません。理解するのはメトリクスパスだけです。各メトリクスは、その名前によって識別される単なる時系列データであり、あらゆる構造は名前の中へ直接エンコードする必要があります。もしその構造が欠けていたり、一貫性がなかったりすると、アラートはデフォルトでノイジーになります。その結果、システム全体の挙動を理解するのではなく、個別メトリクスへ反応し続けることになります。
この記事では、まさにその基盤部分へ焦点を当てます。サービスと、その内部コンポーネント(本記事ではこれを「シグナル」と呼びます)を反映する形で、どのようにメトリクス構造を設計するべきかを解説します。これにより、後のサービスレベルアラートを実現するための基盤が作られます。これは、Graphiteにおけるアラートノイズ削減シリーズの第1回目です。次回以降の記事では、この概念を土台として、メトリクスをどのようにアラートへグループ化するか、さらに高度なアラートロジックをどのように適用するかを解説していきます。
1: 前提条件
この記事は、「メトリクス生成元を自分で制御できるGraphiteメトリクス」を扱っていることを前提としています。実際には、通常これは、自分自身のコードや計測処理から出力されるアプリケーションレベルまたはサービスレベルのメトリクスを意味します。(なぜなら、Graphite自体はメトリクスを収集しないためです。)
Graphiteは、エージェントやアプリケーションからプッシュされたデータを受け取り、それぞれのメトリクスを時系列データとして保存します。この違いは重要です。なぜなら、命名の柔軟性は「メトリクスが作成される時点」にしか存在しないためです。
もし、TelegrafやOpenTelemetryのようなシステムエージェントからメトリクスを収集している場合、それらのメトリクスはあらかじめ構造化されていることが多くあります。それらに対してクエリやアラートを実行することは可能ですが、命名方法を完全には制御できません。そのため、クリーンなサービスレベルグループ化を設計する自由度が制限されます。
この記事のパターンが最も役立つのは、次のような場合です。
- 自分自身のサービスを計測している
- カスタムメトリクスを出力している
- Carbonのような取り込みエンドポイントへデータ送信する前に、命名スキームを設計している
Graphiteでは、各メトリクスパスのセグメント(別名: ディメンション)が明確な意味を持つように、事前に命名階層を定義することが前提となっています。もし、メトリクスがどのようにGraphiteへ送信されるのかに不慣れな場合は、こちらの記事(英語版)が良い出発点になります。
2: なぜメトリクス命名がアラート品質を決定するの
Graphiteは、すべてのメトリクスを独立した時系列データとして扱います。これは、Graphiteにサービスやメトリクス間の関係性に対する組み込み認識が存在せず、グループ化が完全にメトリクス名の構造へ依存しているためです。dot.separated.path 内の各セグメントは階層レベルとして機能し、その階層こそが、Graphiteがデータを整理する唯一の方法です。(一般的なフォルダ/サブフォルダ構造をイメージしてください。)もし命名が一貫していなかったり、フラットだったりすると、グループ化は信頼できないものになります。例えば、ロードバランシング層で次のようにメトリクスが定義されているとします。
lb_forwarder_requests
lb_worker_requests
lb_queue_depth
lb_backend_health
lb_latency_p95
lb_errors
一見すると、これらはすべて同じシステムに関連しているため、問題なさそうに見えます。しかし、Graphiteはそれを理解しません。なぜなら、共有階層が存在せず、文字列内の命名規則しか存在しないためです。これらメトリクスを信頼性高くグループ化することはできず、他システムとの分離も簡単ではありません。環境規模が拡大するにつれて、この管理はさらに困難になります。次に、より構造化された次のアプローチを見てみましょう。
<host>.lb.forwarder.requests.rate
<host>.lb.worker.requests.rate
<host>.lb.queue.depth.value
<host>.lb.backend.health.value
<host>.lb.latency.p95.value
<host>.lb.errors.rate.value
ここでは、構造そのものが意味を持っています。すべてのメトリクスが一貫した階層とサービス境界を共有しているためです。パス内の各セグメントには明確な役割があり、その一貫性によってグループ化の予測可能性が高まります。
また、パス深度が統一されているため、ワイルドカードパターン(*)を使って、異なる形状へ対応する複数クエリを書くことなく、サービス内すべてのシグナルを評価できます。これは、サービス全体へ適用されるアラートを定義する際に特に重要になります。ここで重要なのは、「何を計測しているか」ではなく、「どのように整理されているか」です。
上記構造では:
- 最初のセグメント: ホストまたはインスタンス
- 2番目のセグメント: サービス
- 3番目のセグメント: シグナルまたはコンポーネント
- 残りのセグメント: 計測内容
を表しています。
これにより、明確かつ再利用可能なモデルが得られます。
host => service => signal => measurement
メトリクスがこのパターンへ従うようになると、グループ化は「なんとなく」ではなく、「意図的」なものになります。ワイルドカードは、任意メトリクス集合へ一致するのではなく、システム内の実際の構成要素を表現するようになります。そして、それこそがサービスレベルアラートを可能にする要素です。こちらの記事(英語版)でも、Graphiteメトリクスを一貫性ある形で整理し、適切に命名することがなぜ重要なのかについて、同様のポイントが述べられています。
3: サービスレベルグループ化のためのメトリクス設計
サービスとシグナルを定義する
この構造を有効にするためには、2つの概念を明確に定義すると役立ちます。
「サービス(service)」とは、システム内の論理レイヤーを指します。例えば、ロードバランサー、API、データベース、バックグラウンドワーカーシステムなどです。通常、健全性やパフォーマンスを気にする単位が、このサービスレベルです。
「シグナル(signal)」とは、そのサービス内に存在するコンポーネントや挙動であり、サービス健全性を示すものです。ロードバランシングの文脈では、次のようなシグナルが実際の責務へ対応する例になります。
- forwarder: 上流へのトラフィックルーティングを処理する
- worker: 受信リクエストを処理する
- queue: バッファリングとバックプレッシャーを反映する
- backend health: 上流システムの可用性を表す
- latency: リクエスト処理時間を取得する
これら各シグナルは、1つ以上のメトリクスによって支えられており、命名構造によって単一サービス(例えば lb)の下へまとめられています。Graphiteは、これら関係性を自動では理解しません。だからこそ、適切な命名規則によって、それらを定義することが重要になります。
ワイルドカードグループ化とパス深度
メトリクスが一貫したサービス階層を中心に構造化されると、ワイルドカードクエリは非常に有用になります。
Graphiteでは、パターンを使ってメトリクスグループを選択できます。そして、そのパターンはメトリクスパスへ直接適用されます。パス内各セグメントが安定した意味と一貫した深度を持つ場合、ワイルドカードクエリは「おおよその一致」ではなく、「実際のシステム境界」を表現するようになります。前セクションの構造化例を見てみましょう。
<host>.lb.forwarder.requests.rate
<host>.lb.worker.requests.rate
<host>.lb.queue.depth.value
<host>.lb.backend.health.value
<host>.lb.latency.p95.value
<host>.lb.errors.rate.value
これにより、ロードバランシングサービス内すべてのシグナルを取得する単一パターンを定義できます。(例: *.lb.*.*.*)
各メトリクスが同じ構造へ従っているため、この1つのパターンだけで、全ホストにまたがるサービス全体を評価できます。
一貫性がない場合、論理的には単一システムであるにもかかわらず、それを表現するために複数のワイルドカードパターンを書く必要が出てきます。これは、ダッシュボードやアラートルールへ複雑性を追加し、シグナル漏れや重複の可能性を高めます。構造化されていれば、ワイルドカードクエリはシステム内の実際のコンポーネントへきれいに対応します。任意メトリクス集合へ一致するのではなく、サービスとその内部で動作する全コンポーネントを表現できるようになります。
これは特にアラート設計で重要になります。構造化されていれば、ワイルドカードクエリはシステム内の実際のコンポーネントへきれいに対応します。任意メトリクス集合へ一致するのではなく、サービスとその内部で動作する全コンポーネントを表現できるようになります。これは特にアラート設計で重要になります。各シグナル(またはコンポーネント)ごとに別々のアラートを作る代わりに、サービス全体の状態を評価し、問題発生時にどのシグナルが原因だったのかを特定できるようになります。Graphiteのクエリモデルは完全にメトリクスパスへ基づいているため、グループ化を考慮したパス設計こそが、これを可能にする要素です。
長期的に機能する命名規則
メトリクス命名は初期段階では柔軟に感じられます。しかし、システム規模が大きくなるにつれて変更が困難になります。なぜなら、各ユニークメトリクス名は、それぞれ独立した時系列データとして保存されるためです。ダッシュボード、アラート、クエリがその構造へ依存し始めると、変更には大規模な修正が必要になることが多くなります。そのため、早い段階で一貫した階層を定義しておく価値があります。Graphiteでうまく機能するシンプルなパターンの1つは次の通りです。
<host>.<service>.<signal>.<signal>.<measurement>
例えば:
webserver-0001.lb.queue.depth.value
webserver-0001.lb.latency.p95.value
この構造によって、階層の予測可能性が維持され、パス内各セグメントへ明確な意味を持たせられます。また、「簡潔さ」よりも「明確さ」の方が重要です。つまり、メトリクス名は、「作成時だけ分かる名前」ではなく、「数か月後でも理解できる名前」であるべきです。Graphiteの階層ドキュメントでも、変動性の高いディメンションは階層の深い位置へ配置することが推奨されています。これにより、システム進化後もワイルドカードクエリが期待通り機能し続けやすくなります。環境規模が拡大するほど、一貫性こそが監視システム保守性を支える要素になります。
その他、よく使われるメトリクスセグメントには次のようなものがあります。
- environment(prod, staging, dev)
- region(us-east-1)
- availability zone(us-east-1a)
- app-name
- cluster
命名が予測可能であれば、クエリはシンプルになり、アラート保守は容易になり、監視システム全体の管理もしやすくなります。
4: MetricFire Hosted Graphiteでこれらの概念を適用
Hosted Graphiteでは、この構造はメトリクス探索時にすぐ役立つようになります。
Hosted Graphiteのワイルドカードクエリは、メトリクスパス内の固定位置に対して動作します。つまり、パターンは異なるパス深度をまたいで貪欲(greedy)には一致しません。同じサービス内のメトリクスで構造が一貫していない場合、それらすべてを取得するために複数のワイルドカードパターンが必要になることがよくあります。例えば、*.lb.* のようなパターンは、その正確な深度を持つメトリクスにしか一致しません。次のような、より深いパスは自動では含まれません。
<host>.lb.queue.depth.value
このため、一貫したメトリクス構造が重要になります。サービス内すべてのメトリクスが同じ深度へ従っていれば、単一のワイルドカードパターンだけでサービス全体を表現できます。次の構造化例を見てみましょう。
<host>.lb.forwarder.requests.rate
<host>.lb.worker.requests.rate
<host>.lb.queue.depth.value
<host>.lb.backend.health.value
<host>.lb.latency.p95.value
<host>.lb.errors.rate.value
この場合、ロードバランシングサービス内の全シグナルメトリクスを、単一パターンでクエリできます: *.lb.*..
これにより、関連性のないメトリクスを手動で組み合わせる必要なく、同一サービス内で異なるコンポーネントがどのように動作しているかを確認できます。これが、Grafanaダッシュボード上での *.lb.*.*.* の見え方であり、同様のクエリをHosted Graphite Alertに定義するにも利用できます。
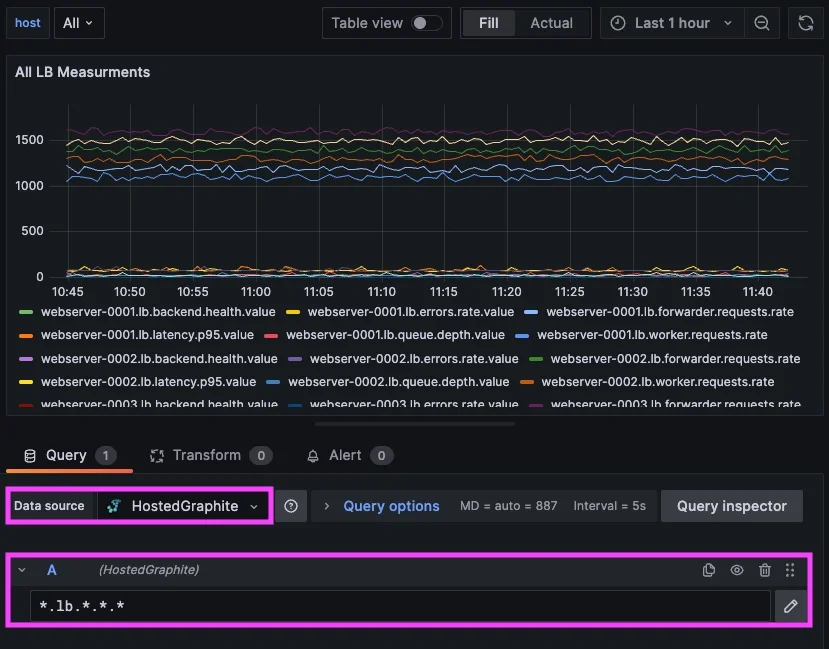
実際には、これによってシステム全体の挙動理解が大幅に容易になります。例えば、queue depth、request rate、latency、backend health のようなシグナルを、すべて同一サービス(lb)スコープ内で一緒に確認できます。このコンテキストこそが、メトリクス命名が一貫していない場合に失われがちな要素です。そして、ここで実運用経験が重要になります。
MetricFireでは、自社アラート基盤内でまさにこの問題へ直面しました。具体的には、受信トラフィックを処理するルーティングレイヤー内です。そのレイヤーでは複数コンポーネントが同時に障害を起こす可能性があり、それぞれが独自アラートを生成していました。その結果、同じ根本原因を指しているにもかかわらず、大量のアラート群が発生していました。
アラートを、より一貫性のあるサービス&シグナル階層へ再構築した後、それらコンポーネントを単一の「サービスレベル」アラート配下へグループ化できるようになりました。これにより、サービス全体の健全性評価、および問題発生時にどのシグナルが原因だったかの特定が可能になりました。また、MetricFire内部基盤でサービスレベルアラートとコンポジットロジックをどのように活用し、アラートノイズ削減と運用可視性向上を実現したのかについての実例ケーススタディもご確認いただけます。
Hosted Graphiteでは、この構造がダッシュボードやアラート構築方法へ直接反映されます。クエリは予測可能なパス構造へ依存するため、よりシンプルになります。また、アラートルールは個別メトリクス単位ではなく、サービス全体に対して動作できるようになります。
このシリーズの次回記事では、
について詳しく解説します。
まとめ
アラートノイズは、アラート設定そのものだけが原因で発生することはほとんどありません。そしてGraphiteでは、その原因は通常「メトリクス名の構造不足」にあります。
Graphiteは、データ整理を完全にメトリクスパスへ依存しているため、命名がすべての基盤になります。もしメトリクスが、DreamFactoryのようなプラットフォームを使用してデータソースから取得される場合でも、サービスとその内部シグナルを中心に構造化されていなければ、グループ化は信頼できないものになり、アラートはノイジーになります。一貫した階層を導入することで、次のことが可能になります。
- サービス単位でメトリクスをグループ化する
- 内部コンポーネント同士の関係性を理解する
- システム挙動に基づいたアラートを定義する
次回の記事では、この概念をさらに発展させ、ワイルドカードグループ化を使ってサービスレベルアラートを作成する方法と、問題発生時に「原因となったシグナルのみ」を表示する方法を解説します。