


Table of Contents
Great systems are not just built. They are monitored.
MetricFire runs Graphite and Grafana as a fully managed service for growing engineering teams, taking care of storage, scaling, and version updates so your team doesn't have to. Plans start at $19/month, billed per metric namespace rather than per host, and include engineer-staffed support. Integrations work natively with Heroku, AWS, Azure, and GCP, and data is stored with 3× redundancy in SOC2- and ISO:27001-certified data centres.
Kubernetes namespaces enable you to organize cluster objects, such as applications, devices and variables. Once you define namespaces, you can use this classification to filter, group and manage objects. You can use the same namespaces in duplicated environments and apply policies to specific clusters segments. Kubernetes namespaces are also important for defining roles and ensuring proper access configuration.
If you're monitoring Kubernetes, you should try out MetricFire. MetricFire runs a hosted Prometheus solution to manage your Kubernetes monitoring. You should sign up for a free trial here, or book a demo and talk to the team directly.
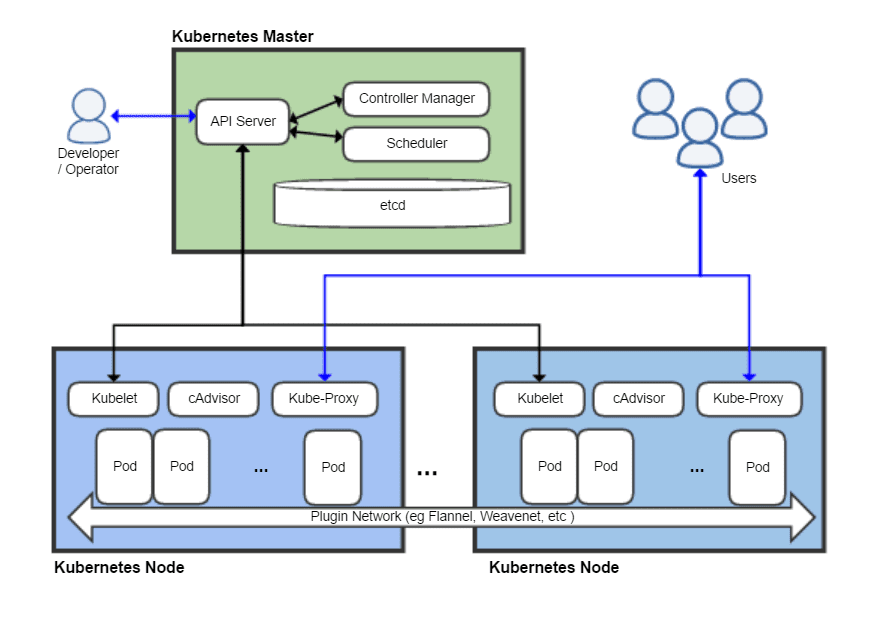
What Are Kubernetes Namespaces and Why Are They Important?
Namespaces are a means to group, filter, and manage groups of objects in a cluster. Namespace objects can be devices, applications, or even variables. In Kubernetes, objects typically refer to containers or pods, but may also be ConfigMaps, secrets, or other entities. Each object is assigned to one namespace to ensure that objects can be identified consistently.
The purpose of Kubernetes namespaces is to define a scope for object names. This enables you to use the same name in other namespaces without the objects getting confused. For example, you can contain the same objects and object names in duplicated environments, like test or dev.
With namespaces, you can apply policies to specific segments of your clusters, such as defining resource policies to limit resource consumption. Or, if using a container network interface (CNI), you can apply network policies that define inter-pod communications.
Namespaces are also important for securing Kubernetes, because it enables you to define role-based access controls (RBAC). This requires defining a role object type and then assigning the created role definition to through role binding. In this case, the Role is applied to the namespace and the RoleBinding is applied to the specific objects within the namespace. For teams managing complex multi-tenant clusters or microservices architectures, proper identity and access management through namespaces can be enhanced by platforms like DreamFactory, which provides governed API access with role-based controls for secure data integration across your infrastructure.
The “Default” Namespace
In a standard Kubernetes distribution, your clusters are automatically assigned the namespace “default”. This is one of three starting namespaces in any deployment. The other two are kube-system, which is applied to Kubernetes components, and kube-public, which is applied to public resources.
While the latter two namespaces should generally be left alone, you should never use the default namespace, especially once you move to production. If you do not change this namespace, you may accidentally overwrite or disrupt configurations later on.
How to Create Namespaces
To create namespaces in Kubernetes there are two steps you need to perform:
Defining namespaces through JSON
First you need to create a YAML file that defines namespaces as seen below:
Execute the following command:
kubectl create namespace exampleSpace --dry-run -o yaml
apiVersion: v1
kind: Namespace
metadata:
creationTimestamp: null
name: exampleSpace
spec: {}
status: {}
}
}
Applying namespaces through kubectl commands
Next, you need to apply the definitions you created. You can do this with the following command:
kubectl create namespace namespace-example --dry-run -o yaml
After you execute the command, you can verify the creation with the following:
Kubectl get namespaces
Working With Namespaces
After you define your namespaces, you need to be able to work with specific ones. This requires assigning contexts which you can switch to as needed.
Define a context
To assign a context, execute the following command:
kubectl config set-context example --namespace=exampleSpace --cluster=minikube --user=minikube
Switch contexts
Once assigned, you can switch to that context as needed. Switching contexts enables you to execute commands within that namespace. To switch, use the following command:
kubectl config use-context example
If you aren’t sure which context you’re currently in, you can check using:
kubectl config current-context
Or, if you aren’t sure what objects are in your current namespace, you can check using a command like one of the following:
kubectl get pods
kubectl get deployments
How Many Namespaces Should You Create?
The number of namespaces you need depends on how you want to organize your deployment and your overall number of objects. For example, small teams are unlikely to need as many namespaces as mature deployments running enterprise Kubernetes. When defining your Kubernetes namespaces, consider the following:
Small teams
When working with a small team or deployment (roughly five to ten microservices) you should be able to stick to one or two namespaces. The only reason to create more namespaces is if there are several teams working on the same project, or several independent components.
Rapidly growing teams
Once you reach more than 10 microservices, you should be considering multiple namespaces. At this scale, you probably have multiple teams working on different projects and need to avoid configuration and deployment conflicts. The best way to ensure that changes don’t negatively impact your workflows is to give at least one namespace to each team or project.
Large businesses
When you reach the size of a large business you have multiple teams that may or may not be in communication. At this scale, you may also have more complex orchestration tooling, such as service contracts or service meshes. This is also when organizations tend to begin using Kubernetes deployments with multiple clusters and possibly persistent objects.
To ensure that these deployments continue to operate as expected, you need to assign one or more namespaces to each team. This enables you to set up resource quotas or any other individual specifications you need without conflict.
Enterprises
The granularity that is required at the enterprise scale requires numerous namespaces, per team and possibly per service. At this scale, you also need to be automating much of your deployment which requires careful naming to avoid undue difficulties.
When creating your Kubernetes namespaces, make sure that each space is clearly defined and easily identifiable by anyone who may need it. Additionally, at this scale you should consider restricting creation and modification of objects on a namespace the user does not own. This can help ensure that even if namespaces are similar, unapproved changes cannot be made.
Conclusion
Kubernetes namespaces enable you to configure and organize cluster objects. In particular, namespaces have a critical role in RBAC. To avoid misconfiguration vulnerabilities, once you deploy Kubernetes in production environments you should change default namespace settings.
If you're monitoring Kubernetes, you should try out MetricFire. MetricFire runs a hosted Prometheus solution to manage your Kubernetes monitoring. You should sign up for a free trial here, or book a demo and talk to the team directly.


