

Table of Contents
Great systems are not just built. They are monitored.
MetricFire is the fully managed Graphite and Grafana platform for small teams that don’t want to self-host their monitoring stack. Pre-built dashboards, alerts, and native add-ons for Heroku, AWS, Azure, and GCP. All with dedicated support and no infrastructure to maintain.
NVIDIA DCGMモニタリングを今すぐ実現したいですか?このガイドでは、DCGM Exporterのインストール方法、/metricsのスクラップ方法、Grafanaでの可視化方法、そして電力、エラー、使用率に関するアラートの設定方法を解説します。
はじめに
GPUはもはやグラフィックス用途だけのものではありません。大量の並列処理が必要な現代のコンピューティングにおいて、GPUは主要な処理エンジンとなっています。CPUが少数のスレッドを高い性能で処理するよう設計されているのに対し、GPUは数千もの処理を同時に実行できるように設計されているため、AIモデルのトレーニング、科学シミュレーション、大規模データセットの処理などに最適です。
ただし、この高い処理能力にはトレードオフもあります。消費電力の増加、発熱の増大、そして注意して管理しないとボトルネックになり得るメモリシステムなどです。
GPU監視が重要な理由はここにあります。監視を行わないと、サーマルスロットリングによって性能が低下したり、最悪の場合ハードウェアの故障を引き起こしたりして、リソースを無駄にしてしまう可能性があります。
このガイドでは、GPUメトリクスを収集するためにNVIDIAのDCGM Exporterをセットアップする方法を解説します。また、Telegrafを使ってそれらのメトリクスをスクレイピングしMetricFireに送信して保存・可視化する方法もご紹介します。
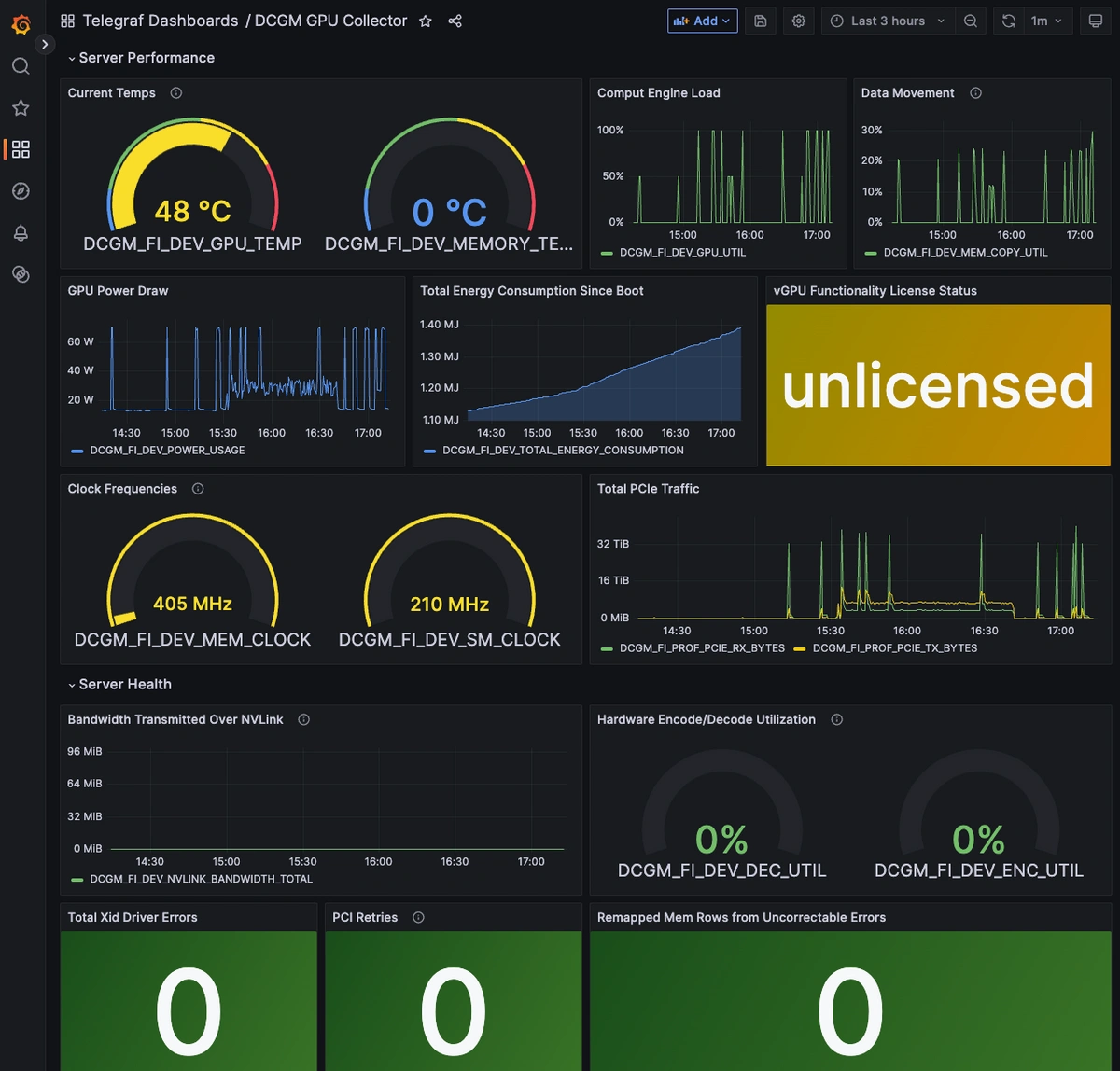
MetricFireのHosted Graphiteプラットフォームを活用し、システムのパフォーマンス分析とエラーのトラブルシューティングを実施しましょう。MetricFireの詳細やシステムとの統合方法については、当社チームによるデモをご予約ください。GPUの重要な指標を確認する第一歩として、MetricFireの無料トライアルにぜひサインアップしてください。
ステップ 1:NVIDIA DCGMとは?(なぜスポットチェックより優れているのか)
ほとんどのGPUサーバーには、NVIDIAのSystem Management Interface(SMI)が標準で搭載されています。これは、パフォーマンスやハードウェアの状態を確認するためのコマンドラインツールです。このツールを利用できる代表的なGPUには、Titanシリーズ(Titan RTX、Titan V、Titan Xp) やRTX 30XXシリーズ(RTX 3060、RTX 3070、RTX 3080、RTX 3090)などがあります。
nvidia-smiコマンドを実行すると、GPU使用率、メモリ消費量、温度、消費電力といったリアルタイムの利用状況を確認できます。GPUが正常に動作しているかを素早く確認するには、最も手軽な方法です。
今回は、HetznerのGEX44 GPUサーバー(Ubuntu 22.04)を立ち上げ、GPUメトリクスを取得し、長期的なパフォーマンス監視のために可視化する方法を検証しました。
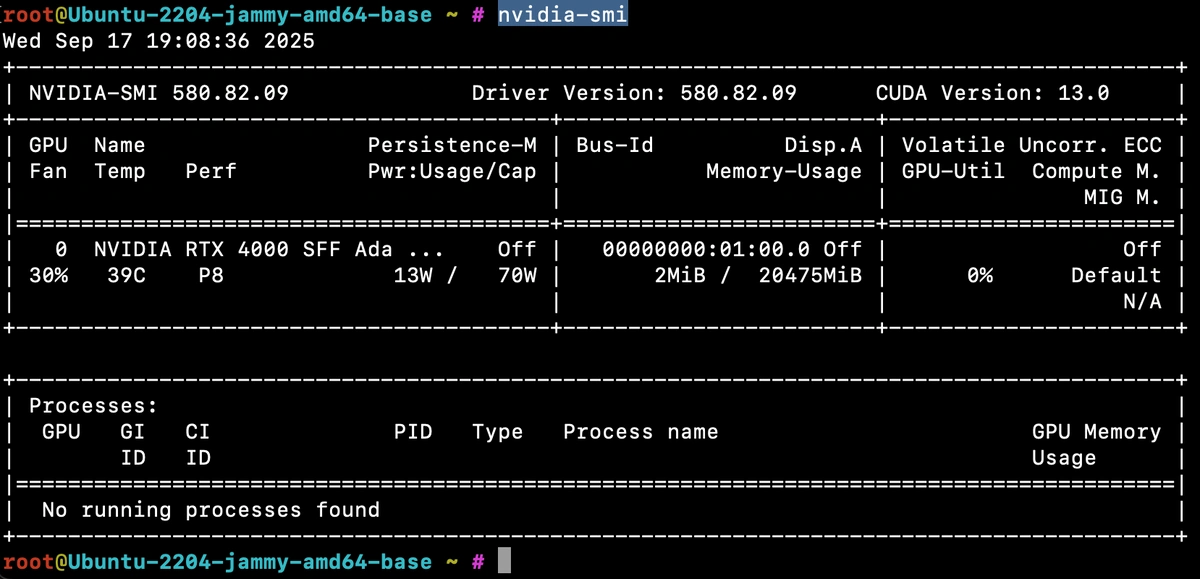
SMIはスポット的な確認には優れているものの、ダッシュボードやアラートで利用できるような継続的なメトリクスのストリームは提供しません。そこで登場するのがNVIDIA DCGM(Data Center GPU Manager)です。DCGMは同様の低レベルのテレメトリデータをHTTPエンドポイントとして公開し、Telegraf、OpenTelemetry、Prometheusなどでスクレイピングできるようにします。取得したメトリクスはMetricFireのHosted Graphiteバックエンドに保存され、長期的な監視に活用できます。
ステップ 2:NVIDIA DCGMでGPU監視|クイックスタート
DCGMとdcgm-exporterをインストールする
NVIDIAのData Center GPU Manager(DCGM)は、サーバー環境でGPUを監視・管理するための低レベルツールキットです。GPU使用率、メモリ、温度、消費電力、信頼性カウンターなどの詳細なテレメトリを取得でき、nvidia-smiのようなスポットチェック用ツールでは得られない情報も確認できます。
DCGM単体では、GPU統計情報にアクセスするためのランタイムとAPIを提供します。これにDCGM Exporterを組み合わせることで、これらのメトリクスをPrometheus形式でHTTP経由で公開できるようになります。これにより、Telegraf、OpenTelemetry、Prometheusなどのコレクターがメトリクスをスクレイピングできるようになります。
セットアップコマンド(Ubuntu 22.04)
まず、NVIDIAのキーリングをインストールし、公式リポジトリを追加します。これにより、Ubuntu 22環境で apt を使って必要なパッケージを取得できるようになります。
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
GPU統計情報を提供する低レベルのホストエンジンとライブラリをインストールします。dcgm-exporterがNVIDIAドライバと通信してメトリクスを収集するために必要です。
sudo apt-get install -y datacenter-gpu-manager
DCGM Exporter は小さなHTTPサーバーを起動し、ポート9400でGPUメトリクスをPrometheus形式で公開します。Telegrafなどのコレクターは、このエンドポイントをスクレイピングしてメトリクスを取得します。
sudo snap install dcgm
sudo snap start dcgm.dcgm-exporter
メトリクスエンドポイントの確認
エクスポーターが正常に動作しているか確認するため、メトリクスエンドポイントをクエリします。GPU温度、消費電力、クロックスピードなどの情報が表示されます。
curl localhost:9400/metrics | head -20
ステップ 3:Telegraf(またはPrometheus)でスクレイピング
サーバー上でTelegrafがまだ動作していない場合は、便利なHG-CLIツールを使って、Telegrafのインストールと設定をすばやく行えます。
curl -s "https://www.hostedgraphite.com/scripts/hg-cli/installer/" | sudo sh
注:Hosted GraphiteのAPIキーの入力が求められ、収集したいメトリクスセットを選択するプロンプトが表示されます。このCLIツールは、出力先を自動的にHosted Graphiteアカウントへ設定します。
インストール後、Telegraf設定ファイル(/etc/telegraf/telegraf.conf)を開き、以下のセクションを追加してTelegrafがメトリクスエンドポイントをスクレイピングするように設定します。
[[inputs.prometheus]]
urls = ["http://localhost:9400/metrics"]
Grafanaで可視化(MetricFireダッシュボード)
設定ファイルを保存したら、Telegrafサービスを再起動してGPUパフォーマンスメトリクスをHosted Graphiteへ送信します。または、構文エラーや権限エラーを確認するために、手動で実行することもできます。
telegraf --config /etc/telegraf/telegraf.conf
これらのメトリクスが Hosted Graphiteアカウントに送信されると、カスタムダッシュボードやアラートの作成に利用できます。
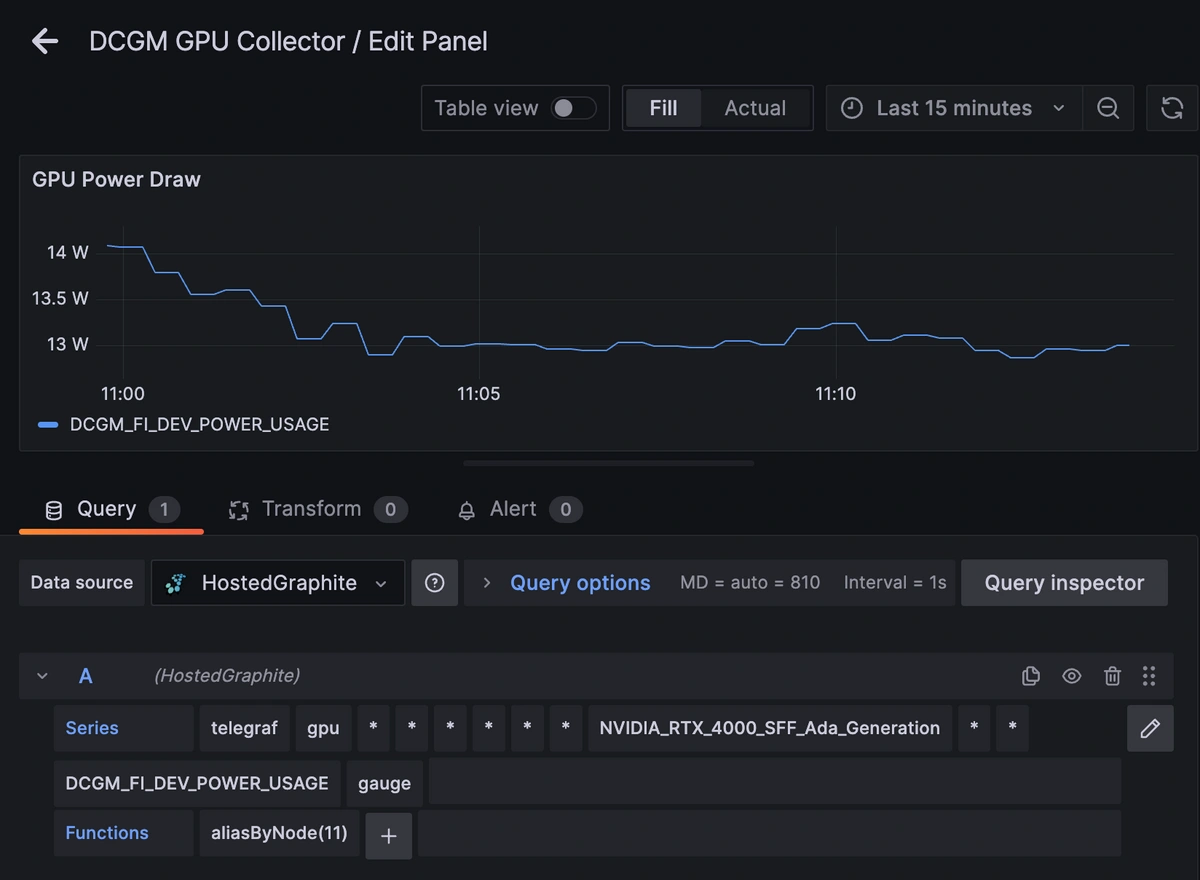
メトリクスがHosted Graphiteに送信されたら、GrafanaにログインしてGPUパフォーマンスダッシュボードの作成を開始できます。
MetricFireのGrafanaダッシュボードを確認する
Telegrafインテグレーションの詳細はこちら
Hosted Graphiteアカウントをお持ちでない場合は、無料トライアルに登録してAPIキーを取得してください。
ステップ 4:追跡すべき主要なDCGMメトリクス(チートシート)
DCGM Exporterが起動して実行されると、さまざまなGPUメトリクスが自動的に収集され、Hosted Graphiteのバックエンドへ転送されます。これらには、使用率、メモリ、温度、電力、帯域幅、さらにはハードウェアの健全性指標まで含まれます。以下では、収集される最も有用なデフォルトメトリクスの概要と、それぞれが何を表しているか、および測定単位を紹介します。
| メトリクス | 説明 | 単位 |
|---|---|---|
| GPU使用率 (DCGM_FI_DEV_GPU_UTIL) | GPUコアの計算エンジンの負荷 | % |
| 消費電力 (DCGM_FI_DEV_POWER_USAGE) | 現在のGPUの電力消費量 | W |
| GPU温度 (DCGM_FI_DEV_GPU_TEMP) | GPUコアの温度 | °C |
| メモリ温度 (DCGM_FI_DEV_MEMORY_TEMP) | VRAMモジュールの温度 | °C |
| フレームバッファ使用量 (DCGM_FI_DEV_FB_USED) | 現在使用中のVRAM容量 | MiB |
| Xidエラー (DCGM_FI_DEV_XID_ERRORS) | ドライバが報告した致命的エラーの数 | count |
| ECCリマップ行数 (DCGM_FI_DEV_CORRECTABLE/UNCORRECTABLE_REMAPPED_ROWS) | メモリの健全性を示す指標 | count |
信頼性メトリクス(Remaps、Retries、Errors)
remapped rows、PCIe replay counters、Xid errorsといったメトリクスは、パフォーマンス指標というよりも健全性指標として設計されています。正常なGPUでは、これらの値は0のままであるはずです。0以外の値が出るということは、ハードウェアが本来必要のない補正や再試行を行ったことを意味します(例えば、ECC障害によりメモリの行が再マッピングされた場合や、送信エラーによりPCIeパケットが再送された場合など)。これらのカウンターが増加している場合、VRAMの故障、信頼性の低いPCIeバス、またはより深刻なハードウェア/ドライバの不具合といった、根本的な不安定さの兆候である可能性があります。本番環境では、これらは「レッドフラッグ」メトリクスとされるため、0以外の値が確認された場合は調査が必要です。
ステップ 5:実際の問題を検知するアラート
劣化の初期兆候を検出するために、次のようなアラートを設定します。
-
GPU Utilization <10% が5分以上継続 → 使用率が低すぎる、またはジョブが停止している可能性
-
Xid Errors >0 → ドライバまたはハードウェアの不安定性の可能性
-
Power Usage がTDPの90%を超える → サーマルスロットリングが発生する可能性
-
ECC Remaps が増加 → メモリ劣化の可能性
ステップ 6:DCGM Exporterのトラブルシューティング
-
/metrics が空の場合:
dcgm-exporterが実行中であること、また、DCGM ランタイムがドライバのバージョンと一致していることを確認してください。 - ECCフィールドが表示されない場合:コンシューマー向けGPUではECC情報が公開されないため、これは想定された動作です。
-
コンテナ環境で問題がある場合:DockerやKubernetesでDCGMを実行する際はNVIDIA Container Toolkitを使用してください。
gpu-burnを使ったGPUストレステスト
gpu-burnは、GPUを100%の使用率まで負荷をかけるCUDAベースのストレステストツールです。バーンインテストや、高負荷状態での安定性を検証するためによく使用されます。
まず、コンパイルに必要なビルドツールとCUDAツールキットをインストールします。
sudo apt-get update
sudo apt-get install -y git make gcc nvidia-cuda-toolkit
次に、gpu-burnのリポジトリをクローンし、バイナリをコンパイルします。
git clone https://github.com/wilicc/gpu-burn.git
cd gpu-burn
make
最後に、gpu-burnを2分間実行します(必要に応じて時間は調整してください)。
./gpu_burn 120
実行中は、DCGMメトリクス上でGPU使用率、消費電力、温度が急上昇する様子を確認できます。
GPUサーバーが多くの電力を消費する理由
GPUは、現代のコンピューティングインフラの中でも特に電力消費が大きいコンポーネントの一つです。CPUとは異なり、GPUはアイドル時でも積極的に消費電力を下げることが少なく、コアやメモリをすぐに使用できる状態に保つために、比較的高いベースライン電力を維持します。負荷がかかると、GPUは数百ワット規模の熱設計電力(TDP)に近いレベルまで消費電力が急上昇することがあります。これは、数千の並列計算コアと高帯域のVRAMを同時に動作させ続けるためです。また、アイドル状態であってもメモリのリフレッシュ処理やドライバ管理処理によって、一定の電力が消費されます。これらが時間とともに積み重なることで、大きなエネルギー消費につながります。DCGMのエネルギーカウンターが報告しているのは、まさにこの累積的な電力使用量です。
よくある質問
Q1. NVIDIA DCGMモニタリングを最も早く開始する方法は?
DCGM(datacenter-gpu-manager)とdcgm-exporterをインストールし、http://localhost:9400/metricsを確認します。その後、Telegraf または Prometheusでスクレイピングし、Grafanaでグラフ化します。
Q2. 最初にどのDCGMメトリクスにアラートを設定すべきですか?
まずはGPU Utilization、GPU/Memory Temperature、Power Usage、Xid errors、ECC remap countersから始めるとよいでしょう。これらのメトリクスは、サーマルスロットリング、不安定性、またはVRAMの故障といった問題を早期に検知できます。
Q3. DCGMは、モニタリングにおいてnvidia-smiよりどのように優れていますか?smiはスポットチェックには非常に便利ですが、DCGMは使用率、メモリ、電力、信頼性指標などのストリーミング形式のメトリクスを提供し、ダッシュボードやアラート用途に設計されています。
Q4. Kubernetesで dcgm-exporter を実行できますか?
はい。DaemonSetとして実行することで、各GPUノードがメトリクスを公開し、PrometheusやTelegrafなどのスクレイパーがクラスター全体から収集できるようになります。
Q5. 一部のECCメトリクスがGPUに表示されないのはなぜですか?
一部のコンシューマー向けGPUは、ECC機能をサポートしていないため、該当するDCGMフィールドは仕様上表示されません。
まとめ
最新のGPUサーバーは、AIやHPCの基盤となる存在です。その効率性と信頼性は、GPU使用率、温度、消費電力を常に可視化できているかに大きく依存します。NVIDIA DCGM MonitoringをTelegraf経由でMetricFireのHosted Graphiteに統合することで、障害の予防、パフォーマンスの最適化、エネルギーコストの管理に必要な可観測性を得ることができます。
最新のGPUサーバーは、AIや高性能計算の中核を担っており、最速のCPUでも処理が難しいようなワークロードを実行可能にします。しかしその一方で、GPUは複雑なハードウェアでもあり、使用率、メモリの健全性、温度、消費電力といった要素が、信頼性や運用コストに直接影響します。GPUの監視は単にパフォーマンスグラフを確認するためのものではありません。ワークロードを効率的に実行し、インフラを安定させ、高額なダウンタイムを回避するために不可欠です。DCGM ExporterやTelegrafのようなツールを可観測性スタックに統合することで、GPUサーバーを透明で測定可能なシステムとして扱うことができます。つまり、GPUアクセラレーションに依存しているのであれば、監視はもはやオプションではありません。それは、これらの強力なプロセッサーが必要なときに確実に性能を発揮し続けるための重要な安全装置なのです。
MetricFireにぜひお問い合わせください。Hosted Graphiteがどのようにモニタリング要件を満たし、あらゆる環境を完全に可視化できるかをご案内します。
MetricFireとのデモを予約するか、無料トライアルに登録して、機能の詳細をぜひご確認ください。

