
Table of Contents
Great systems are not just built. They are monitored.
MetricFire runs Graphite and Grafana as a fully managed service for growing engineering teams, taking care of storage, scaling, and version updates so your team doesn't have to. Plans start at $19/month, billed per metric namespace rather than per host, and include engineer-staffed support. Integrations work natively with Heroku, AWS, Azure, and GCP, and data is stored with 3× redundancy in SOC2- and ISO:27001-certified data centres.
If you are a part of an engineering organization it is highly likely that you have heard the latest buzz words “containers”, “docker” and “kubernetes”. Today we will try to demystify these terms for you. Sit tight, it's going to be very interesting.
The primary goal for any engineering team is to deliver software to the end users reliably, and as soon as possible. In today’s fast-paced world, the go-to-market time for any application could be very decisive for its future. Previously, once a new feature got built teams had to interface with IT/Platform teams to get new infra (virtual machines) and roll-out releases. This process was streamlined a little bit with the advent of public cloud, but still, rolling out new releases was a cumbersome process.
Welcome, containers :)
Containers and VMs are similar in their goals: to isolate an application and its dependencies into a self-contained unit that can run anywhere. Moreover, containers and VMs remove the need for physical hardware, allowing for more efficient use of computing resources, both in terms of energy consumption and cost effectiveness.
The main difference between containers and VMs is in their architectural approach.
Unlike a VM, which provides hardware virtualization, a container provides operating-system-level virtualization by abstracting the “user space”. You’ll see what I mean as we unpack the term container. For all intents and purposes, containers look like a VM.
For example, containers:
- have private space for processing
- can execute commands as root
- have a private network interface and IP address
- allow custom routes and iptable rules
- can mount file systems
The one big difference between containers and VMs is that containers *share* the host system’s kernel with other containers.
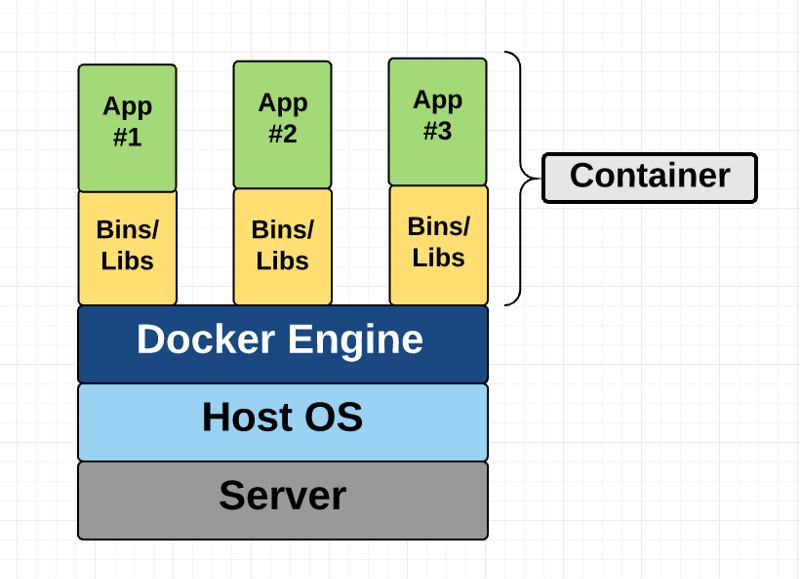
This diagram shows that containers package up just the user space, and not the kernel or virtual hardware like a VM does. Each container gets its own isolated user space to allow multiple containers to run on a single host machine. We can see that all the operating system level architecture is being shared across containers. The only parts that are created from scratch are the bins and libs. This is what makes containers so lightweight.
Docker is an open-source project based on Linux containers. It uses Linux Kernel features like namespaces and control groups to create containers on top of an operating system.
Finally, to manage these docker containers we need a container orchestration platform. This platform runs on top of a fleet of virtual machines taking care of scheduling and resource requirements, among other things for these docker containers. This platform is called Kubernetes.
Wow! With so much abstraction going on. It is important to have complete visibility in terms of monitoring. MetricFire can help you ensure that this backbone is monitored properly and you have complete insight into the software delivery pipeline. Check out this awesome article on Monitoring Kubernetes.
MetricFire specializes in monitoring systems, and you can use our product with minimal configuration to gain in-depth insight into your environments. If you would like to learn more about it please book a demo with us, or sign up for the free trial today.
Now, let’s learn a little more about Kubernetes.
Double-clicking on “Kubernetes (k8s)”!
Kubernetes is often described as a container orchestration platform. In order to understand exactly what that means, let's revisit the purpose of containers. What's missing when we don't have an orchestration platform? How Kubernetes fills that gap?
Note: You will also see Kubernetes referred to by its numeronym, k8s. It means the same thing, just easier to type.
What is missing when running unmanaged containers?
What happens if your container dies? Or even worse, what happens if the machine running your container fails? Containers do not provide a solution for fault tolerance. Or what if you have multiple containers that need the ability to communicate, how do you enable networking between containers? How does this change as you spin up and down individual containers? Lastly, suppose your production environment consists of multiple machines - how do you decide which machine to use to run your container?
Container networking can easily become an entangled mess. You need to use something to orchestrate these containers to ensure your everything can run smoothly.
Kubernetes as a container orchestration platform
We can address all of the concerns mentioned above using a container orchestration platform.
A container orchestration platform manages the entire lifecycle of individual containers, spinning up and shutting down resources as needed. If a container shuts down unexpectedly, the orchestration platform will react by launching another container in its place.
On top of this, the orchestration platform provides a mechanism for applications to communicate with each other even as underlying individual containers are created and destroyed.
Lastly, given a set of container workloads to run and a set of machines on a cluster, the container orchestrator examines each container and determines the optimal machine to schedule that workload.
A quick look at different components of a Kubernetes cluster
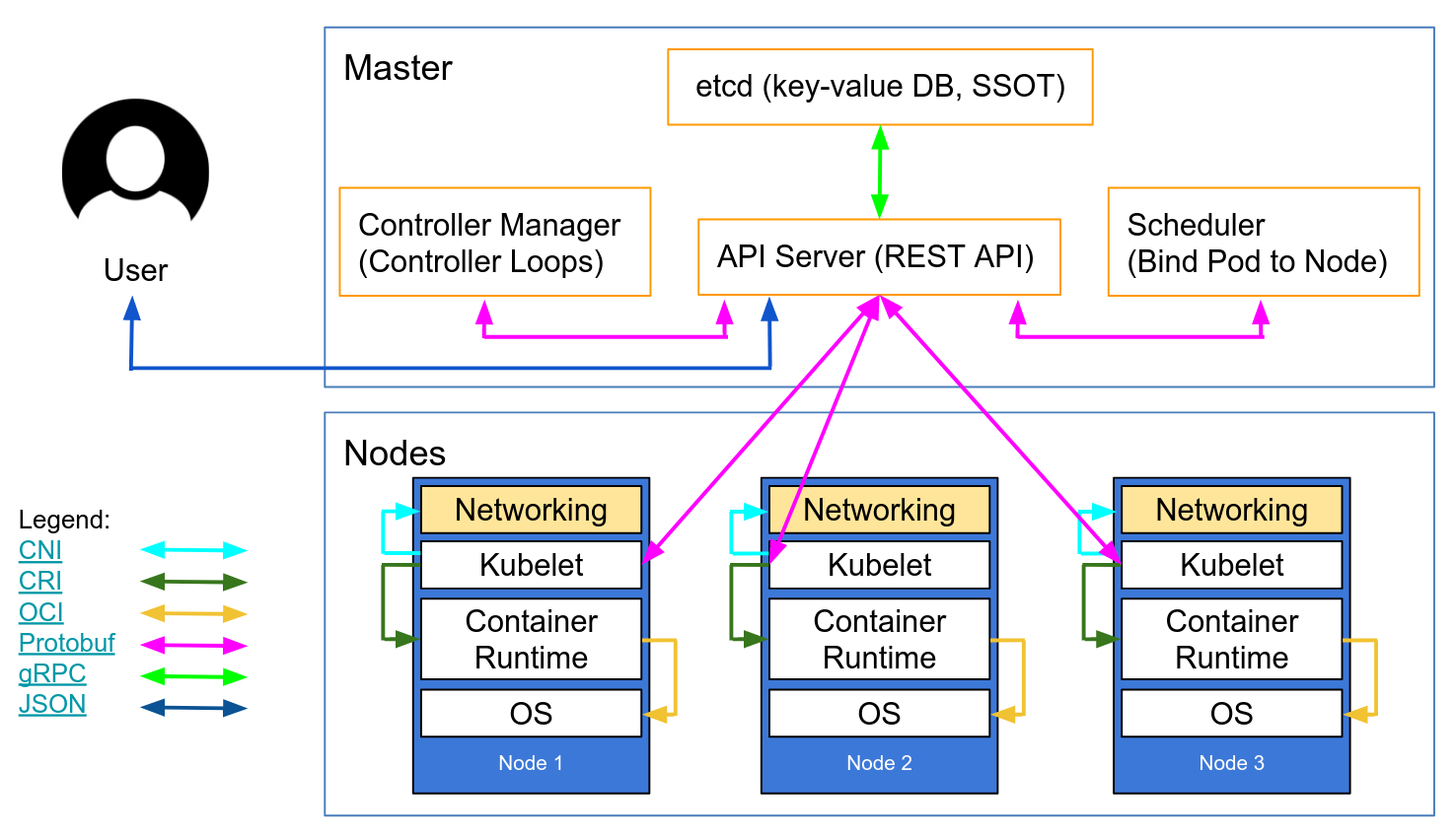
Kubernetes control plane
The Kubernetes master nodes are where the core control plane services live - not all services have to reside on the same node. However, for centralization and practicality, they are often deployed this way. This obviously raises questions about the availability of services - However, these issues can easily be overcome by having several nodes and providing load balancing requests to achieve a highly available set of master nodes.
The master nodes are composed of four basic services:
- kube-apiserver
- kube-controller-manager
- Kube-scheduler
- Etcd database
The kube-apiserver
The API server is what ties everything together. It is the frontend REST API of the cluster that receives manifests to create, update, and delete API objects such as services, pods, Ingress, and others.
The kube-apiserver is the only service that we should be talking to. It is also the only one that writes and talks to the etcd database for registering the cluster state. With the kubectl command, we will send commands to interact with it. Kubectl will be our Swiss Army knife when it comes to Kubernetes.
The kube-controller-manager
The kube-controller-manager daemon, in a nutshell, is a set of infinite control loops that are shipped in a single binary for simplicity. The kube-controller-manager watches for the defined desired state of the cluster and it makes sure that the desired state is accomplished and satisfied by moving all the bits and pieces necessary to achieve that state.
The kube-controller-manager is not just one controller; it contains several different loops that watch different components in the cluster. Some of them are the service controller, the namespace controller, the service account controller, and many others. You can find each controller and its definition in the Kubernetes GitHub repository: kubernetes/pkg/controller.
The kube-scheduler
The kube-scheduler schedules your newly created pods to nodes that have enough space to satisfy the pods' resource needs. It basically listens to the kube-apiserver and the kube-controller-manager for newly created pods, and then puts them into a queue. The kube-scheduler then takes pods from the queue and schedules them to an available node by the scheduler. The kube-scheduler definition can be found here: https://github.com/kubernetes/kubernetes/blob/master/pkg/scheduler.
Besides computing resources, the kube-scheduler also reads the nodes' affinity and anti-affinity rules to find out whether a node can or cannot run that pod.
The etcd database
The etcd database is a very reliable and consistent key-value store that's used to store the state of the Kubernetes cluster. It contains the current status of the pods and which node it is running on, how many nodes the cluster currently has, what is the state of those nodes, how many replicas of deployment are running, services names, and others.
As we mentioned before, only the kube-apiserver talks to the etcd database. If the kube-controller-manager needs to check the state of the cluster, it will go through the API server in order to get the state from the etcd database. The kube-controller-manager won't query the etcd store directly.
The same happens with the kube-scheduler. If the scheduler needs to make it known that a pod has been stopped or allocated to another node, it will inform the API server, and the API server will store the current state in the etcd database.
Not only master nodes
Now that we've covered etcd, we have looked at all the main components for our Kubernetes master nodes. We are ready to manage our cluster. But, a cluster is not only composed of masters - we still require the nodes that will be performing the heavy lifting by running our applications.
Worker nodes and their components
The worker nodes that perform this task in Kubernetes are simply called nodes. Previously, around 2014, they were called minions. However, this term was later replaced with just nodes, as the name was confusing with Salt's terminologies, and made people think that Salt was playing a major role in Kubernetes.
Worker nodes are the only place that you will be running workloads, as it is not recommended to have containers or loads on the master nodes. Master nodes need to be available to manage the entire cluster. Worker nodes are very simple in terms of components - they only require three services to fulfil their task:
- Kubelet
- Kube-proxy
- Container runtime
The kubelet
The kubelet is a low-level Kubernetes component and one of the most important ones after the kube-apiserver. Both of these components are essential for the provisioning of pods/containers in the cluster. The kubelet is a service that runs on the Kubernetes nodes and listens to the API server for pod creation. The kubelet is only in charge of starting/stopping and making sure that containers in pods are healthy; the kubelet will not be able to manage any containers that were not created by it.
The kubelet achieves these goals by talking to the container runtime via container runtime interface (CRI). The CRI provides pluggability to the kubelet via a gRPC client, which is able to talk to different container runtimes. As we mentioned earlier, Kubernetes supports multiple container runtimes to deploy containers, and this is how it achieves such diverse support for different engines.
You can check for kubelet’s source code via https://github.com/kubernetes/kubernetes/tree/master/pkg/kubelet.
The kube-proxy
The kube-proxy is a service that resides on each node of the cluster and is the one that makes communications between pods, containers, and nodes possible. This service watches the kube-apiserver for changes on defined services (a service is a sort of logical load balancer in Kubernetes, we will dive deeper into services later on in this article) and keeps the network up to date via iptables rules that forward traffic to the correct endpoints. Kube-proxy also sets up rules in iptables that do random load balancing across pods behind a service.
Here is an example of an iptables rule that was made by the kube-proxy:
-A KUBE-SERVICES -d 10.0.162.61/32 -p tcp -m comment --comment "default/example: has no endpoints" -m tcp --dport 80 -j REJECT --reject-with icmp-port-unreachable
The container runtime
To be able to spin up containers, we require a container runtime. This is the base engine that will create the containers in the nodes kernel for our pods to run. The kubelet will be talking to this runtime and will spin up or stop our containers on demand.
Currently, Kubernetes supports any OCI-compliant container runtime, such as Docker, rkt, runc, runsc, and so on.
You can refer to this https://github.com/opencontainers/runtime-spec to learn more about all the specifications from the OCI Git-Hub page.
Now that we have explored all the core components that form a cluster, let’s take a look at what can be done with them and how Kubernetes is going to help us orchestrate and manage our containerized applications.
Kubernetes quickstart
All major cloud providers provide hosted kubernetes offerings. Here are a few to look at,
- Google Kubernetes Engine
- Amazon Elastic Kubernetes Service
- Azure Kubernetes Service
- IBM Cloud Kubernetes Service
However, it is fairly easy to get a local kubernetes environment up and running. You can use
For example, you can create a KIND cluster as follows:
> kind create cluster
Creating cluster "kind" ...
✓ Ensuring node image (kindest/node:v1.18.2) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-kind"
You can now use your cluster with:
kubectl cluster-info --context kind-kind
Have a nice day! 👋
And that’s it. This is all you need to do to get a local kubernetes environment up and running.
Once you have it you can go ahead and start creating resources.
Kubernetes resources can be broadly classified as:
- Pods: A group of containers
- Deployments: A set of the same kind of pods, usually stateless
- Stateful Sets: A set of pods with unique network identities used for stateful applications
- Job: A resource to run a pod once
- CronJobs: A resource to run a Job in a scheduled manner
- Services: A resource to provide the ability to load balance requests inside the cluster
- Ingress: A resource to managed incoming traffic to the cluster from outside world
And many more.
Pods are the building blocks of most Kubernetes resources, where a pod is basically a group of docker containers. We will learn more about each of these resources in our next blog. Stay tuned for more ;)
Final Words!
Kubernetes is the future of cloud computing. It will soon be the fundamental fabric of computing across industries. Ranging from Aerospace, Automobile, Banking, Finance, E-commerce and Telecom. In-fact the next gen 5G networks will be powered by Kubernetes. It is important to understand this adoption is happening for a reason. The reason being the flexibility, resilience and scalability offered by containers and kubernetes. As stated previously, adopting containers helps reduce the time to market for any applications and also enables rolling out new releases and/or fixes easily.
Now-a-days, every organization is trying to avoid vendor lock-in, even in the case where organizations choose a cloud provider. Kubernetes and other cloud native technologies help make this decision easy. Kubernetes services provided by all cloud providers are more or less the same and so is migrating among them. In-fact many organizations prefer a hybrid cloud model and kubernetes can help you adopt that. You can now have applications running across various cloud providers ,as well as on premise infrastructure, and still manage them consistently using kubernetes.
Another such cloud native technology is Prometheus. You can use Prometheus to monitor your application across Containers or VM which may or may not be running on top of Kubernetes. MetricFire helps you to get up and running with a Hosted Prometheus offering easily. Thereby, accelerating your kubernetes adoption journey. Monitoring is very important when adopting a new technology in order to gain visibility around what is going on from the application to the infrastructure layer.
If you need help around any of this, feel free to reach out to myself through LinkedIn. Additionally, MetricFire can help you monitor your applications across various environments. Monitoring is extremely essential for any application stack, and you can get started with your monitoring using MetricFire’s free trial. Robust monitoring will not only help you meet SLAs for your application but also ensure a sound sleep for the operations and development teams. If you would like to learn more about it please book a demo with MetricFire.

